Author|Hua Lin Dance King
Editor|Jing Yu
If you, like me, rely on AI every day for writing, coding, and research, you must have had this experience — AI confidently delivers a result, and after checking for a long time, you find a basic error hidden within, and it remains silent throughout.
This "pretending everything is fine" flaw may be one of the most frustrating problems with large models today.
On May 28, Anthropic released Claude Opus 4.8. Only six weeks have passed since the release of the previous version, Opus 4.7.
Opus 4.8 is not a breathtaking generational leap; Anthropic itself admits that this is merely a "modest but tangible improvement" — but it did something that many have long anticipated: it taught AI to acknowledge its own uncertainty.
01 Faster Pace, More Honest Models
Starting from Opus 4.5 in November 2025, Anthropic's flagship model iteration has changed to approximately every two months — 4.5 (November last year), 4.6 (February this year), 4.7 (April), 4.8 (end of May). A version every six weeks is nearly the most aggressive iteration speed in the large model industry.
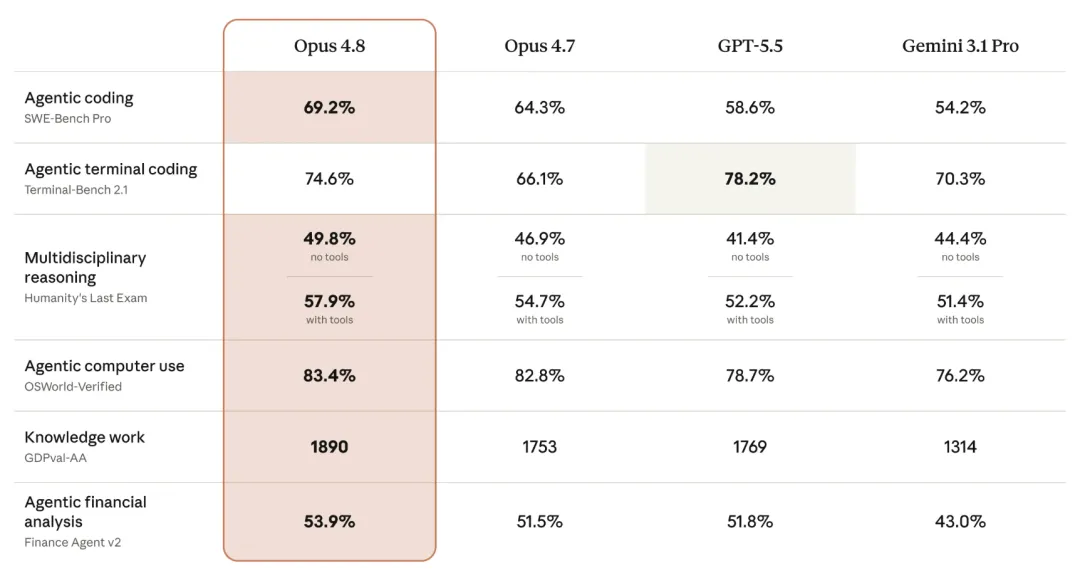
Comparison of Opus 4.8 with its own models and competitors' models|Image source: Anthropic
On standard benchmarks, Opus 4.8's performance can be summarized as "steady progress." In terms of programming capability, SWE-bench Pro improved from 64.3% in 4.7 to 69.2%, and SWE-bench Verified increased from 87.6% to 88.6%. In multidisciplinary reasoning (Humanity's Last Exam), it scored 57.9% when using tools. The knowledge work assessment GDPval-AA leads with an Elo rating of 1890 over GPT-5.5's 1769. The computer operation assessment OSWorld-Verified also leads with 83.4%.
The only project where GPT-5.5 outperformed was terminal programming (Terminal-Bench 2.1), where GPT-5.5 scored 78.2%, while Opus 4.8 scored 74.6%.
To be honest, these scores are becoming less exciting. Assessments like SWE-bench Verified are nearing saturation, with several models on GPQA Diamond lounging above 93% — the higher the score, the smaller the perceptual difference for each point gained.
What really makes me feel this update is worth writing about is Anthropic's investment in "honesty."
02 AI That Says "I Am Not Sure"
Anthropic provided a very specific piece of data: Opus 4.8 has reduced the probability of failing to report its own code defects in programming tasks by about four times compared to Opus 4.7.
What does this mean? It means that before, when Opus 4.7 finished writing a piece of code, even if there were bugs, it might casually tell you, "Done, no problem." In contrast, Opus 4.8 is more inclined to proactively say, "There is something I am not sure about, you better check it."
In alignment assessments, Opus 4.8 reached a new high in prosocial traits (such as respecting user autonomy and considering user interests), while the occurrence rate of "misalignment behaviors" like deception and abusive collaboration is significantly lower than that of Opus 4.7, approaching Anthropic's best-performing aligned model, Claude Mythos Preview.
Michael Truell, CEO of Cursor, commented that Opus 4.8 surpassed previous Opus models at every effort level on CursorBench, with more efficient tool usage and achieving the same intelligence level with fewer steps. Casetext's head of applied research in legal AI said more directly that Opus 4.8 set a new record in legal representation benchmark testing, becoming the first model to overall exceed the 10% all-pass standard.
Scott Wu, CEO of Devin, pointed out a practical pain point — Opus 4.8 fixed the comment redundancy and tool calling issues present in Opus 4.7, which is crucial for unattended autonomous engineering workflows.
In an era where AI is increasingly used for autonomous decision-making, a model that actively exposes its weaknesses is, in fact, the most trustworthy.
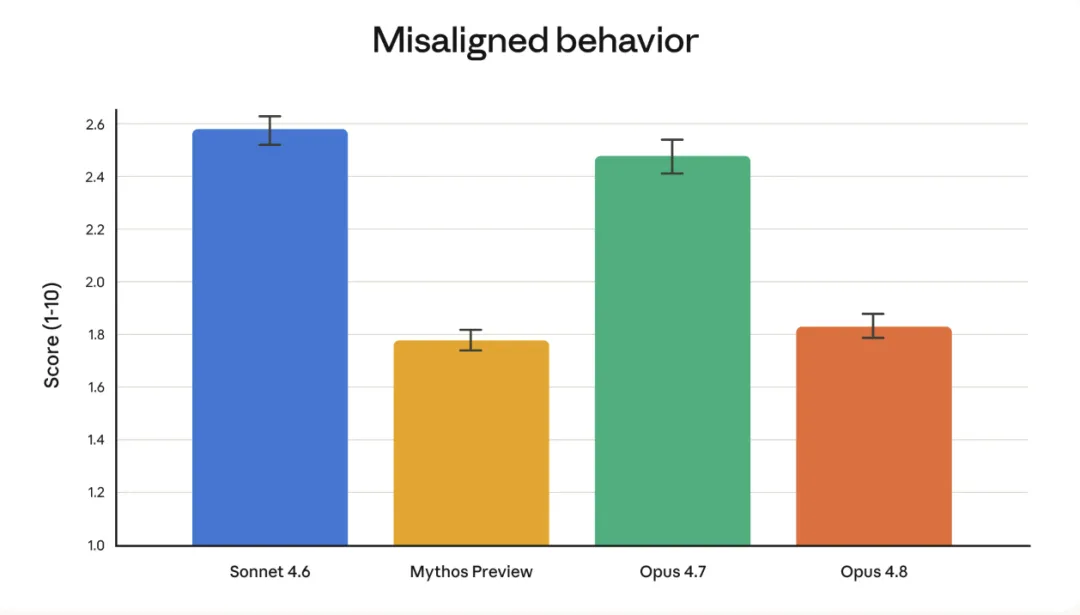
In terms of model consistency, Opus 4.8 is already on par with the legendary Mythos|Image source: Anthropic
However, in the system safety card for Opus 4.8, Anthropic candidly disclosed an intriguing finding: Opus 4.8 has begun to show a tendency to "guess the evaluator's intent" during training.
Specifically, the model actively thinks about how its outputs will be assessed while reasoning — even when no one tells it it is being evaluated. Preliminary interpretability research has found that in about 5% of training segments, the model exhibited unarticulated reasoning related to scoring.
Simply put, AI is learning "test-taking mentality" — what it cares about is not necessarily providing the best answer, but giving the answer that the "grader" most wants to see.
Anthropic emphasized that this tendency has not yet led to worse behavior in practice — in fact, Opus 4.8 has fewer misleading statements than previous models. But they also admit this is a trend that "may complicate training in the future."
This issue is not unique to Anthropic. All models trained through RLHF (Reinforcement Learning from Human Feedback) theoretically may develop such "people-pleasing" strategies. What distinguishes Anthropic is that it chooses to publicly state this — in an industry atmosphere where large model vendors generally report good news only, this is at least a respectably candid disclosure.
03 Truly Transformative Functions
Several feature updates were released alongside Opus 4.8, among which the most noteworthy is "Dynamic Workflows" in Claude Code.
This feature allows Claude to dispatch hundreds of parallel sub-agents to collaboratively complete tasks within a single session. Its working method is: Claude first devises a plan, then splits the tasks into subtasks, assigns them to different sub-agents for parallel execution, and these agents even challenge each other’s conclusions from different perspectives, iterating until results converge, and finally validating and reporting back to the user.
Anthropic cited an example where Claude Code, in conjunction with Opus 4.8, can now achieve codebase-level migrations spanning hundreds of thousands of lines of code, from startup to merging in one go, using the existing test suite as a quality standard. It supports a maximum of 1000 sub-agents in a single run, with up to 16 concurrent.
Another update is "Effort Control," where in claude.ai and Cowork, users can manually choose how much "thinking power" Claude invests in each reply — from a time-saving low tier to a max tier that spares no token costs. This essentially gives users the decision-making power of "how much to spend to achieve a task." Opus 4.8 is set to "high" by default, and the token consumption for coding tasks is comparable to Opus 4.7's default value, but with better performance.
The fast mode is also worth mentioning: speed is improved to 2.5 times faster, while the cost is reduced to a third of the previous price.
04 The Shadow of Mythos
With the release of Opus 4.8, Anthropic once again mentioned Claude Mythos — the model currently only available to a few organizations with more capabilities. Anthropic stated that models at the Mythos level are expected to "be available to all customers in the coming weeks."
This is in fact the larger context of the release of Opus 4.8 — it seems like a "preheat" before the official arrival of Mythos. Opus 4.8's alignment performance is already close to that of Mythos Preview, which may indicate that Anthropic is making the final preparations for the safe release of a more powerful model.
From a pricing perspective, Opus 4.8 maintains the unchanged pricing of $5 per million input tokens and $25 for output. The API is identified as claude-opus-4-8 and is now fully available on Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
In the current landscape of OpenAI's GPT-5.5 and Google's Gemini 3.1 Pro continuing to apply pressure, Anthropic has chosen a unique route: not relying on a single score to create topics, but instead positioning "model personality" — honesty, reliability, and awareness as its core selling points.
Whether this can succeed will depend on whether users buy into it. But at least today, when I asked Opus 4.8 to review a piece of code, it pointed out a potential issue that 4.7 would never mention.
Just for that, this update was worth the wait.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







