AI 最残酷的地方,不是它不给穷人答案。
恰恰相反,它给每个人答案。
它给学生论文框架,给职员邮件模板,给创业者商业计划,给普通人法律解释、投资建议、职业规划。答案第一次如此廉价、如此充足、如此像真的。
但问题也在这里:当答案人人可得,真正稀缺的就不再是答案,而是判断答案的能力。
新的信息穷人,不是被挡在 AI 之外的人,而是已经拿到答案,却没有能力判断答案、也没有条件把答案带入真实机会的人。

一、AI 时代的信息差
互联网时代的信息穷人,是那些被排斥在网络之外的人。解决方案看起来清晰:接通网线,普及设备,提高识字率。搜索引擎时代稍微复杂,你需要学会提炼关键词、筛选来源、判断可信度,最好还懂一点英文。但门槛是可见的,也是可量化的。
AI 时代的信息差,结构完全不同。
大型语言模型不是搜索引擎,它直接替你生成结论。你不需要再去"找"答案——答案会被组织成流畅的段落、清晰的步骤、自信的语气,主动送到眼前。从表面上看,门槛大幅降低了。但这里藏着一个冷酷的结构:当答案变得廉价,错误也同样变得廉价;而辨别"这个答案是否可信"的能力,反而比以往任何时候都更稀缺、更值钱。
历史上每一次通用技术的扩散,都遵循同一个逻辑:新技术先奖励那些已经拥有互补资本的人。印刷术让识字者先受益;电脑让懂办公软件、懂编程的人先受益;互联网让英语能力强、检索技能熟练的人先受益。AI 的互补资本包括教育背景、专业知识、批判性思维、组织授权、付费能力,以及最难被量化的那一样——判断力。
新技术很少先奖励最需要它的人。它通常先奖励最能利用它的人。
二、先分开的,是通向 AI 的路
不平等的第一道裂缝,在你打开应用之前就已划好。
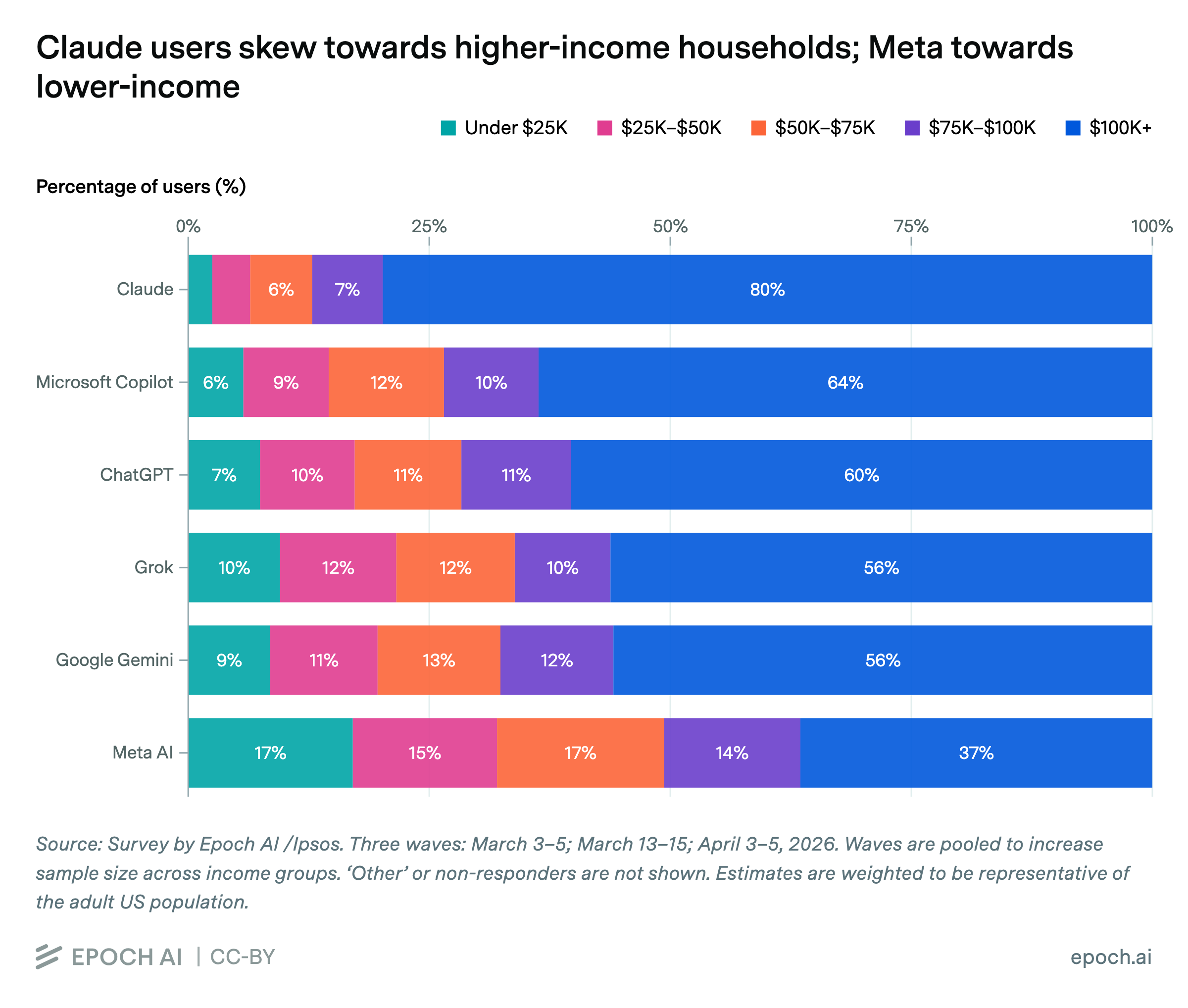
2026 年 4 月,AI 研究机构 Epoch AI 与民调公司 Ipsos 发布了一项针对约 5000 名美国成年人的问卷调查。三轮问卷问的是一个看似普通的问题:过去一周,你使用过哪些 AI 服务?但答案呈现出来的,并不是简单的产品偏好,而是一张收入、入口和分发交织在一起的地图。
Claude 的周活跃用户中,约 80% 来自年收入 10 万美元以上的家庭;Meta AI 用户中,这一比例只有 37%。反过来,Meta AI 用户中约 32% 来自年收入 5 万美元以下的家庭,而 Claude 用户中,这一比例仅为 7%。
这些数字之所以重要,不是因为它们证明了“有钱人用高级 AI,穷人用免费 AI”。那是最浅的一层读法。更值得追问的是:不同的人,为什么会在日常生活中遇见不同的 AI?
一个人让 AI 给冰箱里的剩菜配一份晚餐,替照片调亮背景,把一条短信改得更得体。另一个人让 AI 整理客户访谈、比较供应商报价、挑出报告里的薄弱假设。两者都在调用同一种技术。但一种调用止于便利,另一种调用进入了收入、职位和谈判权的循环。
差异并不只在用户身上,也在入口身上。Claude 的使用路径需要主动搜索、比较产品、理解能力差异、选择付费,再将工具嵌入工作流——每一步都在筛人。Meta AI 的路径则几乎相反:它被内置在社交平台里,免费、低摩擦,用户往往在刷动态、发消息或看照片的间隙被动遇见。
这不是一个关于品味的市场,而是一个关于分发的市场。用户看似在选择工具,工具的价格和入口也在选择用户。
来源:epoch.ai
三、然后分开的,是使用 AI 的场景
即便你找到了一个好的 AI 工具,第二道分流在公司里等着你。
在普通办公室里,AI 的到来很少以“裁员通知”的形式出现。它先接管会议纪要、邮件草稿、表格整理、客户分类和汇报初稿。对管理者而言,这些自动化释放出时间,让他们去做判断;而对新人和基层员工来说,这些自动化拿走的,恰恰是他们证明自己、练习判断、进入更高层级工作的入口。
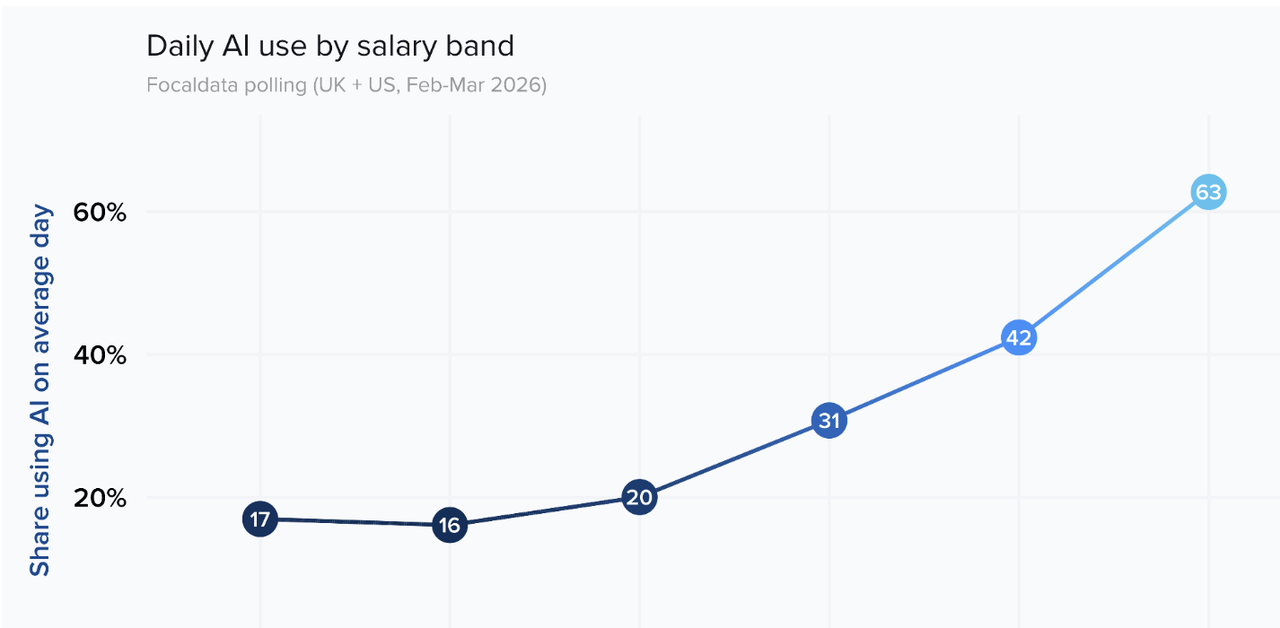
数据比这个场景更冷:Financial Times 与研究机构联合开展的英美劳动力 AI 追踪调查(2026 年 2—3 月,覆盖英美逾四千名受访者)显示,最高薪资档的劳动者中有 63% 在普通工作日使用 AI,而最低两档的比例分别只有 17% 和 16%。这不是一条缓和的坡,这是一道悬崖。
更关键的发现在于驱动因素。这份职场调查的回归分析揭示,薪资对 AI 使用率的影响,在控制其他变量后几乎消失——真正在起作用的是四个因素:年龄、资历、行业,以及培训。其中培训的效应最大:一家提供了正式 AI 培训的公司,员工的日均 AI 使用率比未培训的同类公司高出 37 个百分点。即便只是非正式指导,也有 24 个百分点的提升。
然而现实是:截至 2026 年初,只有 14% 的员工表示曾接受过雇主提供的正式 AI 培训,三分之二的人完全没有接受过任何形式的培训。
AI 培训不是技术问题,是分配问题。谁被选中接受培训,谁就被允许进入生产力增长的轨道;谁没有,工具就只是屏幕上一个没有被授权打开的图标。
AI 在消费端是一个应用,在职场端是一种权限。而权限,从来不是平均分配的。
来源:Focaldata
四、最后分开的,是判断 AI 的能力
这是最隐蔽的一道分流,也是最根本的一道。
设想一个应届毕业生刚刚进入一家咨询公司。他用 AI 生成了一份行业分析报告的初稿,结构完整,数据充足,语气自信。他的上司——一个在这个行业做了十年的人——扫了一眼,指出其中两个数据引用的原始来源存在方法论缺陷,第三个结论的因果关系推导有问题。上司不是因为比他更努力,而是因为他拥有那层底座——知道哪里容易出错,知道哪种流畅是真的流畅,哪种流畅是机器在填空。
这正是职场调查数据里那个反直觉发现的真实含义:AI 在工作中的最重度使用者,不是最年轻的员工,而是已经在当前岗位工作了 2 到 10 年的人。AI 使用率与资历的关系,在控制年龄之后依然显著。这不是因为年轻人不想用,而是因为 AI 的价值,高度依赖于使用者本身已有的判断能力。
经验是 AI 最重要的互补资本,而经验不能被订阅。
AI 降低了"听起来懂"的成本,却没有同等降低"真正懂"的成本。甚至有一个更危险的后果:越是缺乏底座的使用者,越容易对 AI 的输出照单全收;而越是照单全收,判断力就越难生长。代理人替你判断的时候,你在消费智能,不是在积累它。
诺贝尔经济学奖得主、MIT 教授 Daron Acemoglu 对此毫不客气:使用 AI 工具需要一定程度的教育、抽象思维、量化能力和对技术的熟悉度。"AI 要增加不平等,这几乎是确定的,"他说。
新的信息穷人就在这里浮出形状:他们不是没有 AI 的人,而是有 AI、有入口、有答案,却缺乏判断答案的训练;有工具、有场景,却没有把工具产出变成机会的权限;每天消费智能,却从未积累过智能。
五、平权效应的边界
但 AI 与不平等的关系,并不只有扩大差距这一面。
多项实验研究发现,在可控条件下,AI 往往对低技能者的提升幅度更大——对呼叫中心员工、初级写作者、入门级咨询顾问都是如此。这不难理解:顶尖专家从 AI 那里获得的边际增益有限;一个从未能负担专业服务的人,第一次用 AI 读懂一份合同,这本身就是一次质的跃迁。
但这里有一个关键区别需要指出:实验研究测量的是"使用之后的提升",而现实数据测量的是"谁实际在使用"、"谁被允许使用"、"谁使用之后能把结果变成机会"。两组数据都没有说谎,它们测量的是完全不同的事情。
一项技术可以在实验室里缩小差距,同时在现实世界里扩大差距——如果采用本身是不平等的,如果场景本身是不平等的,如果判断力本身是不平等的。
AI 拥有平权的技术特性,却运行在不平等的社会结构里。这两点同时为真,才是问题的真实形状。
六、技术会普及,红利不会同时到达
每一代人都倾向于相信,自己这个时代的通用技术会打破旧的秩序。
印刷术出现之后,识字者先受益了几个世纪。电脑普及之初,它放大的是那些已经会用办公软件和写代码的人的能力。互联网的早期红利,流向了懂英语、会检索、有时间和动机去套利的人。在每一次技术浪潮中,"这次不同了"的声音都很响亮,而结构性的分流往往需要几十年才慢慢变得可见。
AI 的分流速度可能更快,分叉可能更深。因为它影响的不是某一类任务,而是几乎所有依赖判断和语言的工作。而这恰恰是最难被标准化、最难被重新分配的那类能力。
有人认为差距最终会收窄。经济史学家、牛津互联网研究院教授 Carl Benedikt Frey 持这种看法,他的依据是历史:电脑普及带来的不平等,在几十年后随着使用门槛下降而逐渐消解。这个类比不是没有道理。
问题在于,即便接受这个乐观的历史类比,Frey 自己也承认了关键的限定条件:"这取决于差距需要多长时间才能闭合。如果是十年或二十年,那就更令人担忧。"
十年或二十年,不是一个可以轻松等待的时间尺度——对于那些在这段时间里需要找工作、谈薪资、积累经验的人而言,尤其如此。
结语
这是一个奇特的历史时刻:我们第一次拥有了一种技术,它能让所有人都感觉自己正在变得更聪明。
这种感觉,往往就是终点。
问题是,在一个真正由判断力决定输赢的时代,把感觉当终点,可能是最昂贵的一种错误。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





