Written by: Leo
Have you ever thought that programming as we know it might be fundamentally changing? Developers are shifting from merely using AI tools to viewing AI as a new foundation for building software. This is no small adjustment; it’s a complete paradigm shift. Think about it: core concepts that we have always taken for granted—version control, branching, code review, and even the definition of "collaboration"—are being redefined due to AI agent-driven workflows. What shocks me further is that Git, which we use every day, is actually a tool designed for a patch workflow meant for mailing lists from twenty years ago, and now it has to serve a scenario where human developers and a group of AI agents work simultaneously.
This is why the news that GitButler just secured $17 million in Series A funding made me stop and think seriously. This round of funding was led by a16z, followed by Fly Ventures and A Capital. More interestingly, GitButler's CEO Scott Chacon is one of the co-founders of GitHub and has written that book, "Pro Git," that almost every developer has read. Why is someone who has already achieved great success in the field of version control returning to the entrepreneurial track to rethink a problem that seems to have been "solved"? He said plainly in the announcement: "We are not building a 'better Git'; we are building the next generation of infrastructure for how software is built." This statement hides profound insights about the future of software development.
The 20-Year Predicament of Git: A Tool Designed for Mailing Lists
I find that many people do not understand the historical context of Git. Git was originally created by the Linux kernel team in 2005, and its design philosophy is deeply rooted in Unix traditions. Scott mentioned an interesting detail in an interview: the core team of Git never intended to create a user-friendly interface. They adhered to the Unix philosophy, creating a series of low-level "pipe commands," with each command doing one simple thing, which you could then chain together with Perl scripts to accomplish anything you wanted. This design philosophy made perfect sense at the time, as they assumed that only technical experts like the Linux kernel team would use the tool.
What happened next is well-known. A developer named Pasquy wrote some Perl scripts to package a unified user interface for Git, which is what we now use as the CLI commands. These scripts became increasingly popular and were eventually merged into the core of Git, becoming what is now referred to as the "porcelain layer." Interestingly, these commands haven’t seen significant changes since 2005 and 2006. They were originally written in Perl and later rewritten in C, but the core logic and user interface remain almost unchanged. Scott said that the commands he described in the first edition of "Pro Git" in 2009 can still be used as they are today.
This stability is, in some ways, a good thing. The Git team places great importance on backward compatibility; they are unwilling to remove any existing features for fear of breaking the current workflows. But this also raises a fundamental problem: the core assumptions under which Git was designed have become severely misaligned with current software development practices. Git was designed to send patches via mailing lists. In that era, developers would make some changes locally, generate a patch file, and send it via email to maintainers, who would review it and decide whether to accept it. The entire process was asynchronous, text-based, and single-threaded.
And what about now? We have continuous integration, continuous deployment, distributed teams collaborating in real time, code review tools, and various automated testing and deployment pipelines. More importantly, we now have AI agents writing code on a large scale. Scott pointed out an impressive observation: we are now teaching a group of AI agents to use a tool designed for mailing list patches. This sense of dislocation is akin to making a Tesla drive on a road designed for horse-drawn carriages.
The Unix philosophy behind Git poses another issue: it attempts to serve both computers and humans simultaneously through a single interface. When you run "git branch," by default, you only get a list of branches without any user-friendly interface. This is because Git needs to ensure that the output of this command is readable by humans and parsable by other programs. This compromise results in a scenario where Git is not friendly enough for humans and not optimized for computer programs. While some commands offer the "--porcelain" option for machine-readable format, this is not standard practice, and many commands do not even offer this option.
New Challenges in the Age of AI Agents: One Working Directory is No Longer Enough
As AI begins to engage in programming on a large scale, Git's limitations become even more apparent. I have recently tried working with multiple AI agents simultaneously and found that Git's fundamental design assumptions—a single developer, a single branch, a linear workflow—are completely outdated. Modern developers do not work linearly. You might be running several agents at the same time: one fixing a UI bug, another optimizing database queries, and a third updating documentation. But Git's index system would crash under this parallel editing, as it assumes that your local working copy represents a single, atomic modification to the codebase.
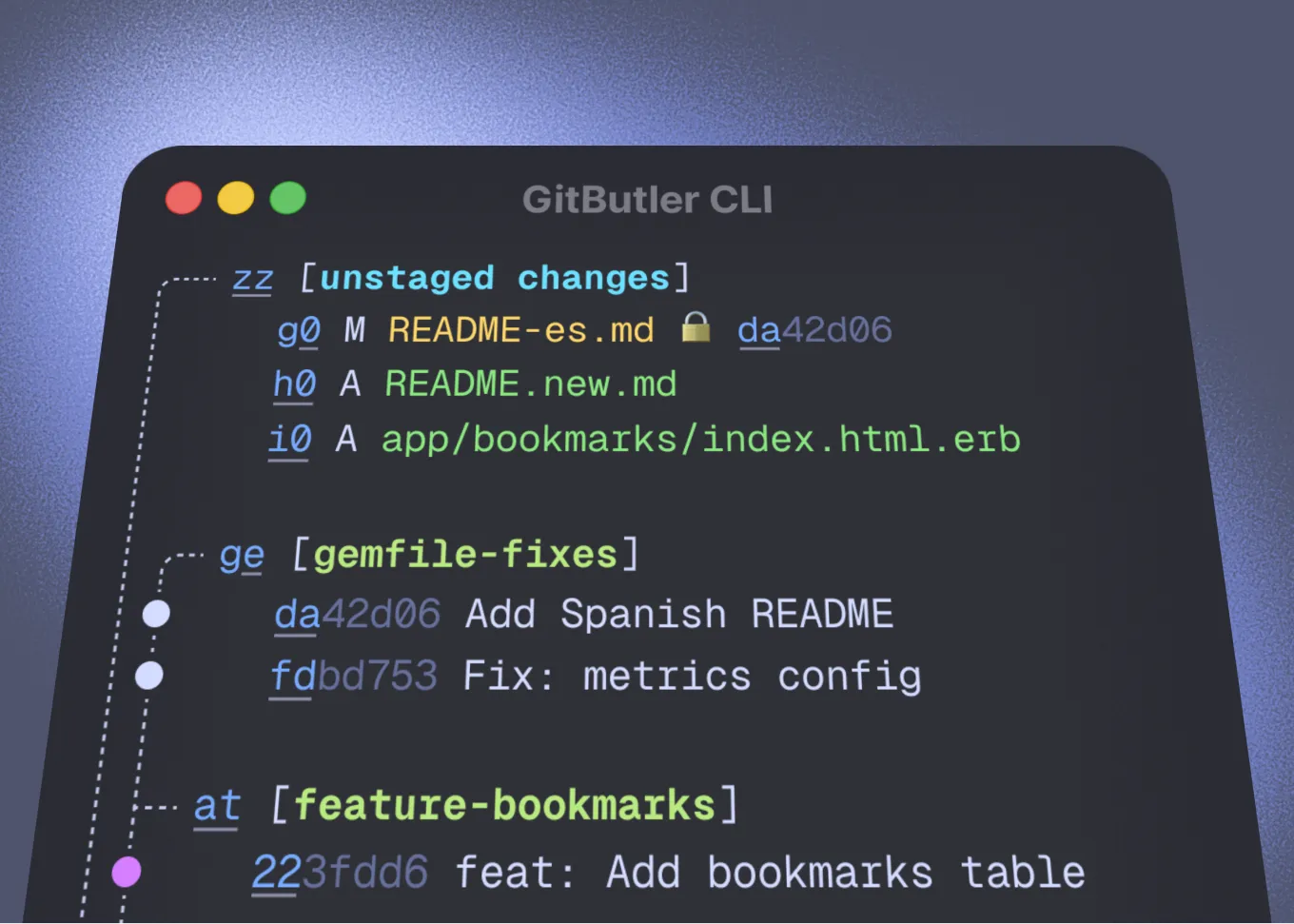
The traditional solution is to use worktrees, which means creating multiple copies of the codebase for each parallel task. But this brings new problems. If you have five agents working simultaneously, you need five complete copies of the working directory. Although Git has optimized at the storage level, it still means a lot of file duplication and disk space usage. More importantly, these agents are completely isolated from each other; they do not see what each other is doing until they each finish and attempt to merge, at which point they discover conflicts. By then, the cost of resolving conflicts is already very high.
The solution proposed by GitButler is parallel branches. This is a design that struck me as brilliant. Parallel branches are like regular branches, but you can have multiple open at the same time. You get the benefit of worktrees (logical isolation) without needing to copy all files. All agents operate within the same working directory, but their modifications are allocated to different virtual branches. Scott described in an interview an impressive scenario: they let two agents work simultaneously, both wanting to edit the same file, but in incompatible ways. What happened? One agent automatically stacked its branch on top of the other agent's branch and continued working, committing to its own stacked section. This intelligent conflict handling would be nearly impossible to achieve in a traditional Git workflow.
I particularly appreciate an experiment by the GitButler team, although they ultimately did not adopt it. They tried to implement a chat channel between multiple agents so they could communicate what they were doing. Scott said the feature looked super cool; they could see the conversations between agents and were very eager to publish it. But after extensive testing, they found that this feature did not actually help. Agents would independently discover that someone else was modifying a file, automatically infer the reasons, and then adjust their work strategies. They did not need explicit communication, as communication itself brought overhead and slowed down the entire process. This finding is enlightening: we cannot simply apply human collaboration patterns to agents; agents have their own ways of working.
Redesigning the User Interface: For Humans, For Agents, For Scripts
The CLI tool recently released by GitButler piqued my interest greatly. It is not a simple Git wrapper; rather, it fundamentally rethinks how command line tools should be designed. Scott mentioned an interesting observation: about 80% of developers still use command line tools to operate Git, even with various GUI tools available. The reason is simple—most Git GUIs merely wrap Git commands with a graphical interface without adding much functionality, and can actually slow down the operation. If you know what command to run, simply typing the command is often faster.
But GitButler’s CLI is different. It provides different output formats for different use cases. If you run a command directly, it gives you optimized, human-readable output, including prompts and suggestions. If you add the "--json" parameter, it provides structured JSON data for easy scripting parsing. They are even considering adding a "--markdown" option specifically to optimize output format for agents, as markdown format is easier to inject into an agent's context.
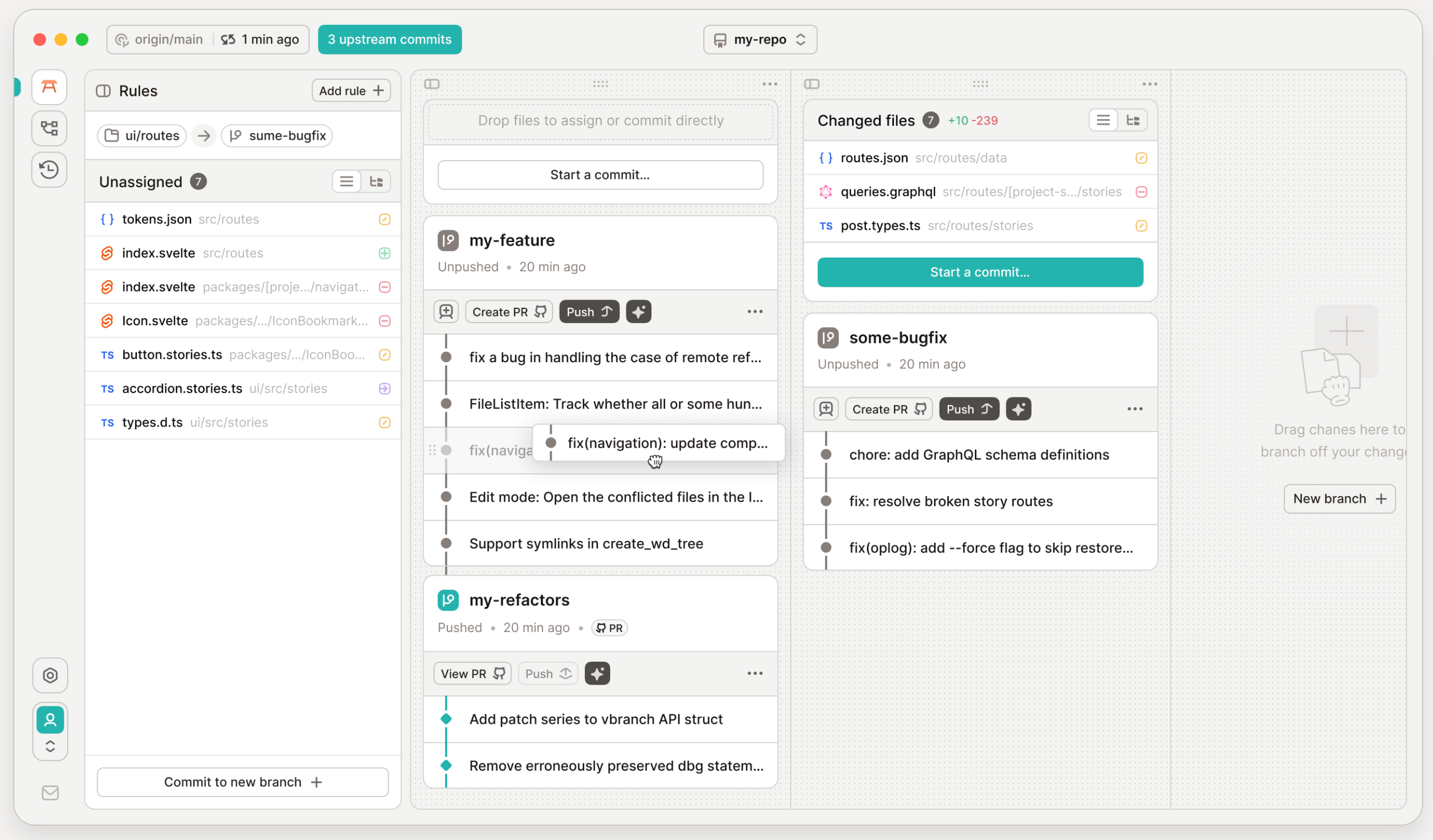
More interestingly, they are optimizing the tool design based on the actual behavior of agents. They discovered that although the "--json" option is provided, agents actually prefer using human-readable outputs and then pipe them to jq or write Python scripts to extract the necessary information. Another finding is that after running any modifying command, agents almost always immediately run "git status" to check the status. So the GitButler team directly added the "--status-after" option to all modifying commands, automatically displaying the status after the operation was completed. This design would not be done in traditional Unix philosophy and is not particularly suited for script programming, but it is perfect for agents.
They are also exploring how to provide more contextual information to agents through output. For example, including hints in the command output such as "if you want to do this, run this command." This is not for humans, as humans would find it verbose, but for agents, this extra context can help them decide what to do next more quickly. Scott said this is a very interesting UX issue because we must treat agents as a new “user persona,” with needs and behavior patterns completely different from humans.
Essential Changes in Software Development: From Writing Code to Writing Specifications
In the interview, Scott mentioned a thought-provoking viewpoint: the best software engineers in the future may not be those who write the best code, but those who communicate best, write well, and describe things clearly. This might sound counterintuitive; after all, many of us chose programming because we could interact with machines, not with people. But upon careful reflection, this trend makes complete sense.
As AI agents can efficiently generate code, the bottleneck is no longer the implementation details but whether you can clearly describe what you want. Scott shared his own workflow: he spends most of his time writing specifications that detail how a feature should work. Whenever a design decision needs to be made, he lets the AI implement it based on the specifications and then tests the results. If there are issues, he goes back to modify the specifications and instructs the AI to reimplement. This loop can be done very quickly because he doesn’t need to handwrite all the implementation code.
The beauty of this way of working is that you can do "show and tell" at any time. Traditionally, if you wanted to validate an idea, you needed to write a detailed technical document and persuade team members to read it and provide feedback. But no document, no matter how detailed, is as intuitive as a working prototype. Now, you can quickly generate a prototype for team members to experience, then rapidly iterate based on feedback. This greatly speeds up the cycle from idea to validation.
But this also brings new challenges. The bottleneck in team collaboration has shifted from "can we implement this feature" to "can we reach a consensus on what we want." Scott said many developers, especially those who consider themselves very smart, feel they don’t need to explain what they are doing; the code itself is the best documentation. But in the AI age, this attitude doesn’t work anymore. You must be able to clearly express your intentions and write specifications that team members and AI can understand. Writing ability has become a new superpower.
This brings to mind the future of code reviews. Scott raised a pointed question: if you honestly ask most software engineers, do you really read the entire PR carefully during code reviews? Do you think through the logic line by line? Do you bring the code down locally to test it? Or do you just skim through it, confirming that it looks fine and approving it? Most people would choose the latter. This is not because developers are irresponsible, but rather because thorough code review is too costly, and the benefits are often not obvious enough.
AI agents may change the game in this regard. Agents excel at reviewing every line of code meticulously, running tests, and checking for potential problems. They don’t get tired, don’t get bored, and can maintain consistent review standards. This way, human reviewers can focus on higher-level issues: does this change align with product direction? Does it address genuine user needs? Is the architecture well designed? And the specific implementation details, syntax issues, and potential bugs can be handed off to AI for checking.
PR and Issue: The 20-Year Collaboration Model Needs to Evolve
The Pull Request mechanism of GitHub has become the standard model for open-source collaboration, but Scott believes there are fundamental issues with this model. PRs are based on branch review, not patch review. This leads to a lot of "commit garbage"—submissions like "oops, fixed a small bug," "forgot to add this file," etc. Because in PR mode, what matters is the entire branch, not individual commits. So no one really cares about the quality of commit messages; the PR description is key, and the PR description is not stored in Git history and is often lost after merging.

In the mailing list era, this was not a problem. Each patch had a carefully crafted commit message because that was your PR description. Review was based on patches, and the quality of patches was directly related to the quality of commit messages. But in the GitHub era, we have lost this constraint. Scott believes that future code reviews should return to the patch-based model but combine it with the advantages of modern tools. Reviews should be local, allowing you to actually run code and test features. Agents can help run various tests and flag potential issues; you only need to focus on parts that genuinely require human judgment.
Another interesting point is about communication between teams. Scott pointed out that one thing software development has historically not done well is real-time communication between teams. If I’m modifying a file and you’re also modifying the same file, we usually only discover conflicts at the merge stage, at which point one person has to bear 100% of the merge work. But what if we could know in real time what each other is doing? For humans, the overhead of this real-time communication might be too great and disrupt workflows. But for agents, this is not a problem. Agents can use their idle time to communicate with each other, understand what others (or other agents) in the team are doing, preemptively identify potential conflicts, or actively adjust work strategies to avoid conflicts.

The metadata system that GitButler is exploring is also quite interesting. They want the ability to attach conversation records, agents' thought processes, and related contextual information to commits or branches. Git currently has very limited support for such metadata. This information can be incredibly valuable in helping understand why a decision was made and what the thought process behind the code is. But it also presents a big data problem. Scott mentioned that even just saving text, the scale of this metadata can grow quickly. They had to leverage technology from large repositories in Git (like those used by Chrome or Microsoft Office teams) to handle this scale of data.
My Thoughts on This Transformation
After reading the story of GitButler and Scott's interview, I have had some profound reflections. Software development is undergoing a fundamental paradigm shift, and version control systems, as the infrastructure of software development, must evolve accordingly. The design principles of Git were advanced twenty years ago, but they have now become limitations. What we need is not a "better Git," but a redesigned infrastructure for modern workflows and the AI age.
I particularly resonate with Scott’s thoughts on "logical endpoints." He said that during his language learning startup, many people saw real-time translation technology and declared that language learning was dead. But he countered that even with a perfect translator, both parties would need to wear the translator, and this mode of communication is far inferior to direct communication in the same language. He once worked in Japan for a week with a translator who was very good, but the experience was still poor; you wouldn’t want to establish deep relationships or engage in complex collaboration this way. The same is true for programming. No matter how powerful AI agents become, they cannot fully replace human judgment, creativity, and communication skills.

Regarding the future of GitHub, I feel that Scott's perspective is very astute. GitHub's greatest advantage is its user base, but its greatest disadvantage is that as a large company, it is hard to pivot quickly. The entire industry is currently exploring what the "next GitHub" is, but Scott points out that this question itself may be wrongly posed. GitHub itself is not the "next" anything; it has created an entirely new collaboration model. Similarly, a completely different, currently unimaginable collaboration model may emerge in the future.
I believe that the value of GitButler lies not only in the specific features it offers but also in the way of thinking it represents. They are questioning the assumptions we have taken for granted: why can we only work on one branch at a time? Why must commits be linear? Why do agents and humans use the same interface? Why must collaboration occur through PRs and issues? This first-principles thinking is precisely what we need in this rapidly changing era.
I also realize that as developers, we need to cultivate new skills. Writing clear specifications, effectively communicating ideas, and understanding how AI agents work—these may be more important than pure coding ability. This might be a challenge for many developers, especially those who chose programming to avoid interacting with people. But this also presents an opportunity for us to free ourselves from low-level implementation details and focus on more creative work: defining problems, designing solutions, and making trade-off decisions.
GitButler’s $17 million funding is just the beginning. I believe that in the next few years, we will see more attempts to rethink the infrastructure of software development. Version control, code review, project management, testing, deployment—these tools were all designed in an era before AI and need to be re-evaluated. Those developers and teams who can adapt to the new paradigm first will gain a significant advantage in this transformation.
In the end, software development will become a job that focuses more on communication, collaboration, and decision-making, rather than syntax and implementation details. This may sound unsettling to some traditional programmers, but I believe it is a good thing. It allows programming to become closer to the essence of problem-solving, rather than being mired in technical details. When we no longer need to remember complex Git commands, no longer need to manually resolve merge conflicts, and no longer need to spend excessive time writing repetitive code, we can focus our energy on the truly important things: understanding user needs, designing elegant solutions, and creating valuable products. This is the core of software development and the direction GitButler is trying to help us return to.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






