Author: APPSO
The worst news for ordinary people is coming.
Just now, Anthropic announced the launch of Claude Fable 5 and Claude Mythos 5.
Among them, Fable 5 is Anthropic's first publicly available Mythos-level model, while Mythos 5 is mainly targeted at a select group of cybersecurity defense agencies, critical infrastructure providers, and biomedical researchers who subsequently enter the trusted access program.

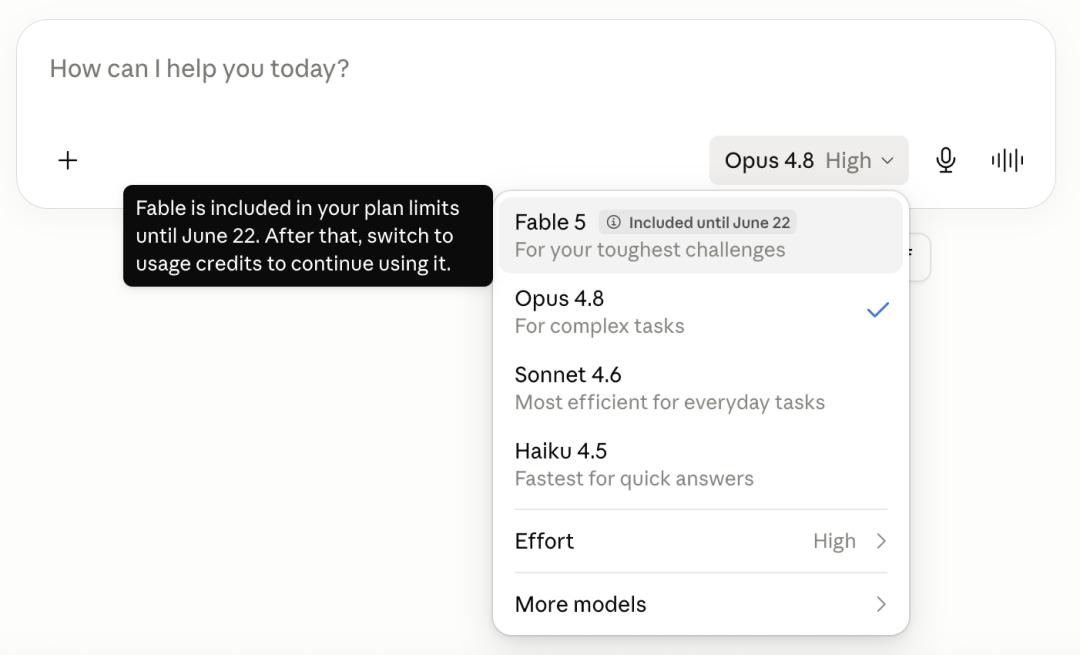
However, few people have noticed that, according to official statements, Fable 5 will be included in the Pro, Max, Team, and per-seat billed Enterprise plans without any additional charge from now until June 22. On June 23, Fable 5 will be removed from these subscription plans, and continued use will require consuming usage credits.
In other words, the past model of unlocking the strongest AI with a single "monthly card" may be gone for good. For users, the future will require consideration not just of subscription prices, but also the real token costs behind each invocation and each long task execution.
Welcome to the era of Token billing.
Claude Fable 5 has made its debut, but it is also the fiercest "Token Assassin"
Anthropic has also provided an explanation for the naming of Fable and Mythos. Fable derives from the Latin word fabula, meaning "a little story being told," which is close in meaning to the Greek word Mythos.
The two new names look like two models, but are actually closer to two versions of the same underlying model. Fable 5 is currently open to the public with stricter safety limitations;
Mythos 5 is currently only available through the Project Glasswing program to a select group of cybersecurity defense agencies and critical infrastructure partners.
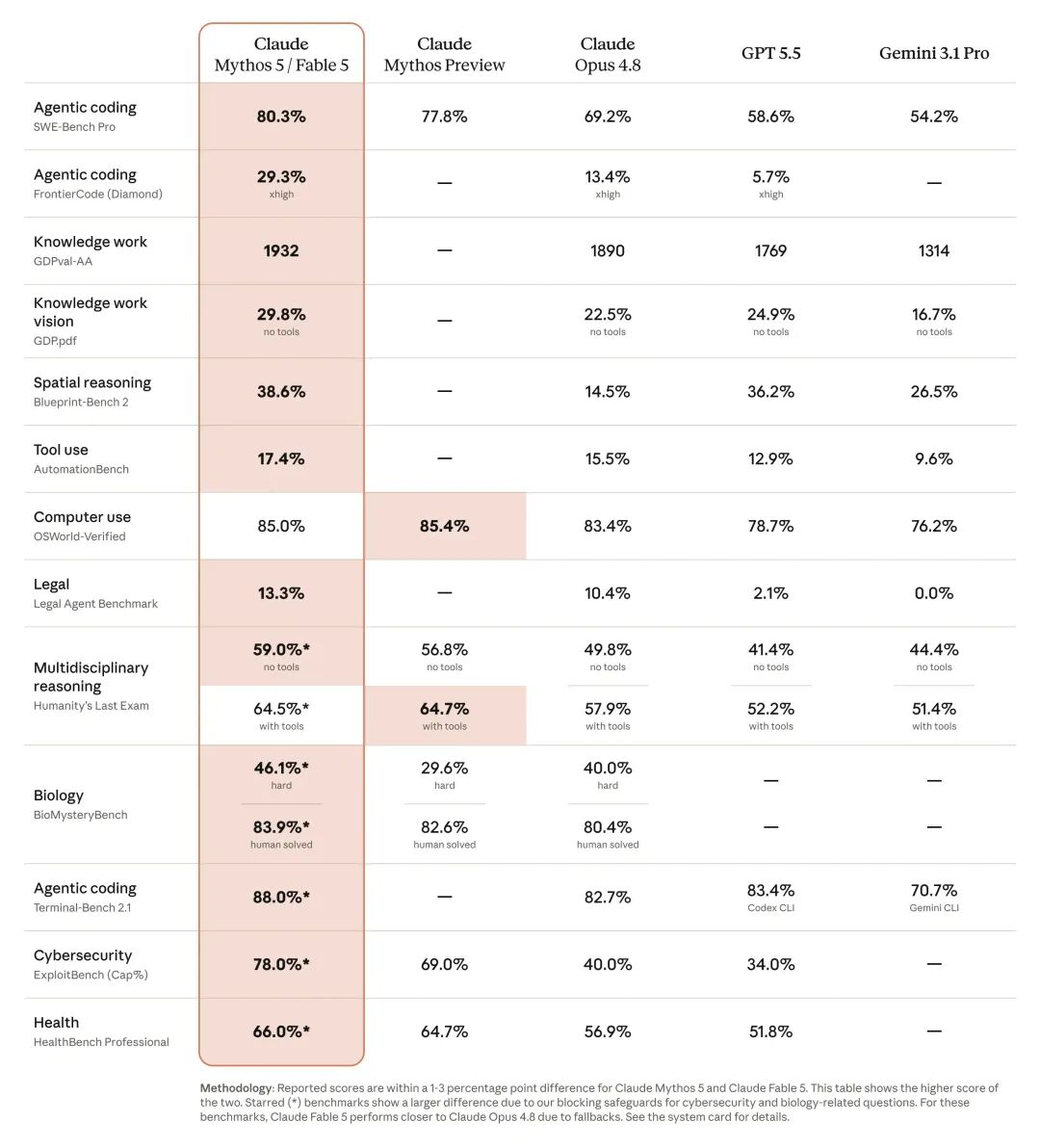
According to the official blog of Anthropic, Fable 5 is the most capable model among the company's general available options, showing significant improvements in software engineering, knowledge work, visual understanding, and scientific research. The longer and more complex the task, the greater the advantage over previous Claude models.
The significance of Fable 5 lies in the large-scale opening of Mythos-level capabilities to ordinary users for the first time. The benchmark test score chart is as follows, highlighting its clear lead.
However, the model name itself has sparked some discussion. Former OpenAI Codex head Tibo humorously pointed out that Anthropic used the Fable name that OpenAI had intended to use but did not.
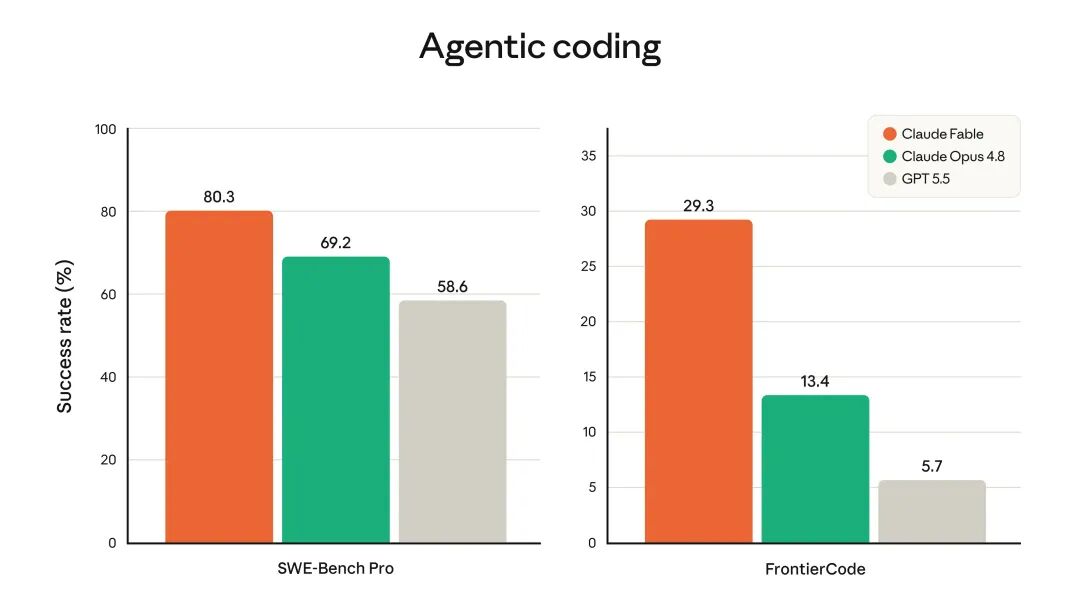
In terms of capability, software engineering is one of the areas most emphasized by the official account.
Anthropic mentioned that Stripe, in early testing, had Fable 5 handle the migration task of a 50 million line Ruby codebase. If this work were handed to an engineering team to complete manually, it would have originally taken over two months, but Fable 5 accomplished it in a day.
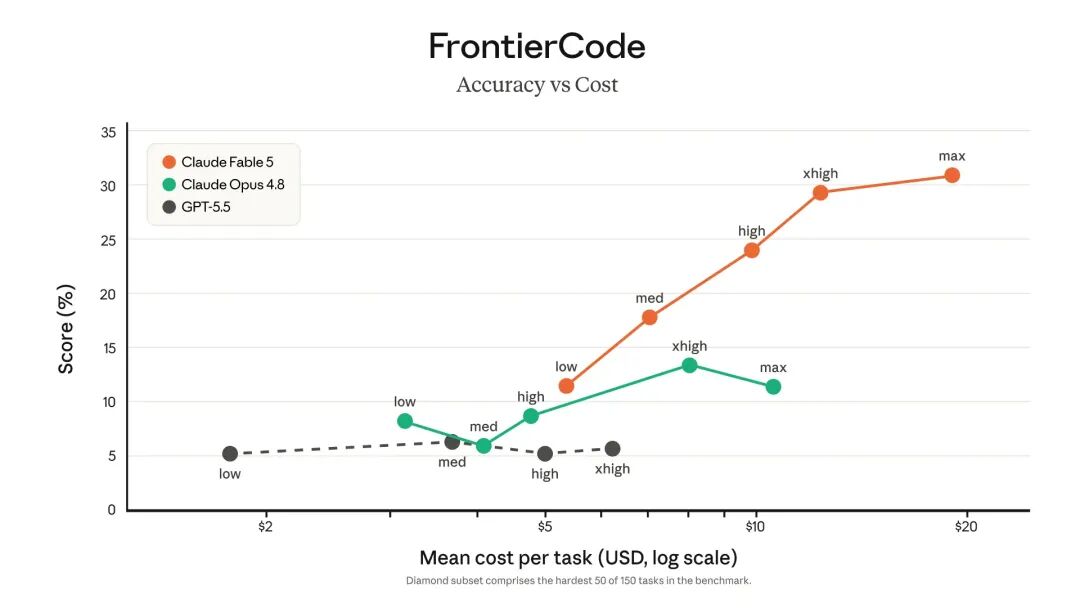
Cognition's FrontierCode test also showed that Fable 5 led in complex production-level coding tasks. This assessment focused not on ordinary coding problems, but on whether the model could complete difficult programming tasks and meet the requirements of high-quality production codebases.
Anthropic also emphasized that Fable 5 is more token-efficient than previous Claude models. Of course, this is something to take with a grain of salt; similar statements have been made with each release of a new Claude model, but they have almost all turned into individual Token Assassins, providing quite a few jokes for the vast Internet.
In knowledge work, Fable 5 achieved the highest score in Hebbia's financial benchmark tests, with improvements concentrated in document reasoning, chart understanding, and complex problem analysis. IMC's trading analysis assessments also showed that Fable 5 performed strongly in fact retrieval, conceptual reasoning, cause analysis, and expected value analysis.
Visual capabilities are also a key focus of the release. Anthropic claims that Fable 5 can extract precise numbers from complex scientific charts and can reconstruct application source code based on webpage screenshots.
The official also demonstrated a more intuitive case: Fable 5 completed Pokémon Fire Red solely relying on gameplay visuals, without using additional maps, navigation tools, or game state information. Previous Claude models required more complex auxiliary systems to accomplish similar tasks.
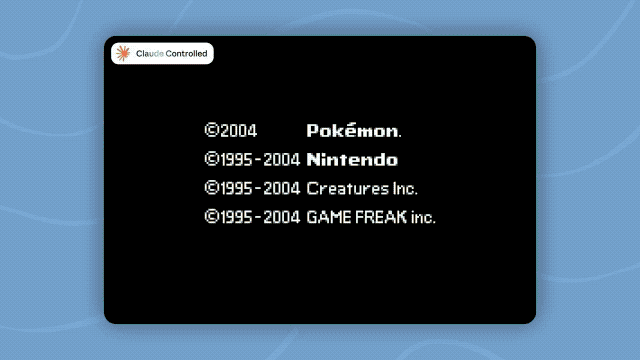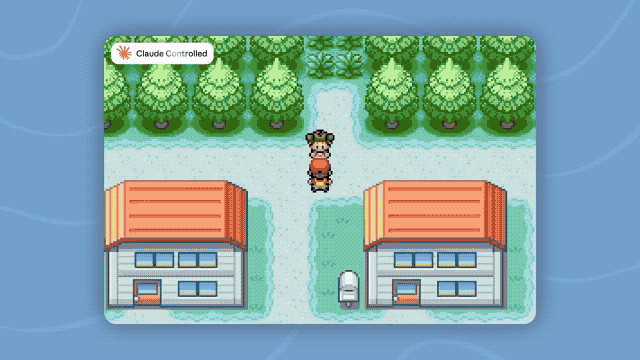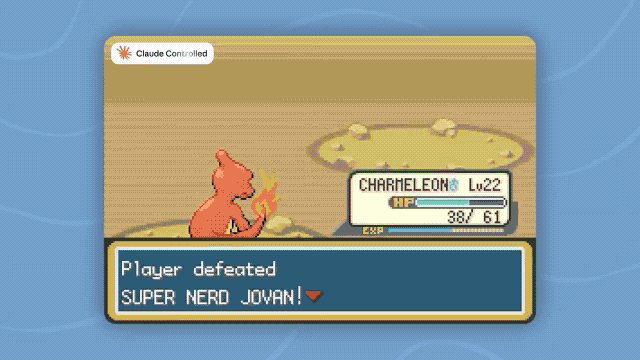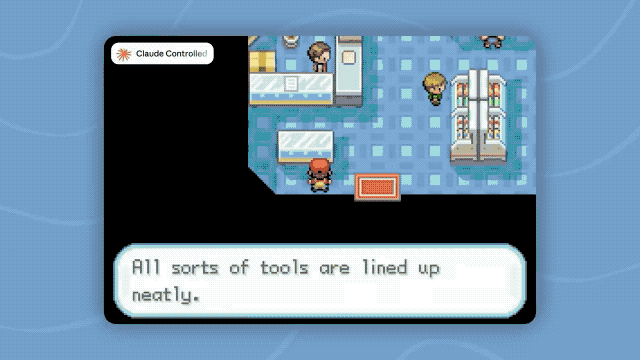
The ability to manage long contexts and memory has also improved. Anthropic found in the Slay the Spire test that after providing the model with persistent file memory, Fable 5's performance improvement reached three times that of Opus 4.8, and the frequency of entering the final chapters also increased threefold.
The life sciences direction is more sensitive. Anthropic states that internal protein design experts used Mythos 5 to accelerate some drug design processes approximately 10 times faster.
In one instance, Mythos 5 utilized protein design and bioinformatics tools to complete a whole set of processes usually handled by scientists, including selecting binding sites, invoking design tools, and processing failure results, without human assistance. Out of 14 protein targets, 9 generated candidates worth further study.
The enhancements in life sciences and cybersecurity capabilities also explain why Anthropic has not fully released the complete Mythos-level capabilities.
When Fable 5 was opened to the public, it was accompanied by a new safety classifier. Whenever user requests involve high-risk areas such as cybersecurity, biology, chemistry, or model distillation, the system will automatically switch to respond using Claude Opus 4.8 and inform the user that the model has changed.
Anthropic stated that in early data, over 95% of Fable 5 sessions would not trigger such a change. Ordinary tasks like writing, programming, analysis, design, and data processing will still largely be able to use Fable 5 itself. However, entering high-risk areas will impose limitations on the model’s capabilities.
Cybersecurity is the area with the strictest limitations. Anthropic admits that the Mythos-level model excels at discovering and exploiting software vulnerabilities and also possesses strong capabilities for agent-based attacks, potentially covering reconnaissance, discovery, lateral movement, and other phases. To prevent such capabilities from being abused, Fable 5’s cybersecurity classifier has a wide coverage.
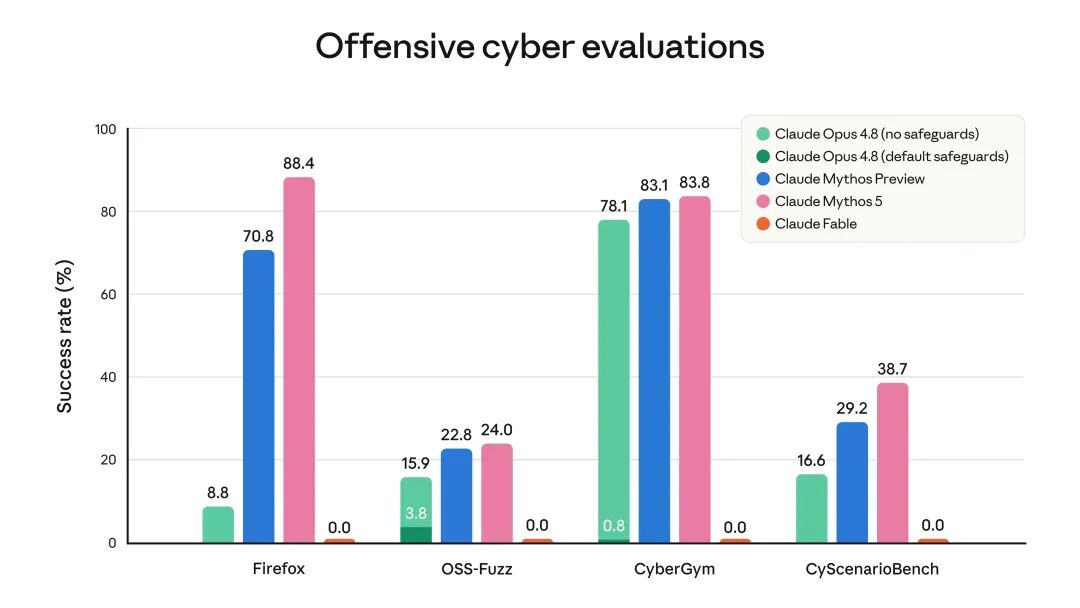
The same goes for biology and chemistry. Anthropic believes that the model possesses the capability to complete real scientific tasks, and the previous approach of blocking only a few questions related to biological weapons is no longer sufficient. Therefore, Fable 5 will temporarily revert to Opus 4.8 for most biology and chemistry-related requests.
It is worth mentioning that Anthropic has also added a layer of hidden protection for Fable 5 against the development of cutting-edge large models.
This mainly restricts Claude from assisting in building pre-training pipelines, distributed training infrastructure, or ML accelerator designs to prevent the model from accelerating the training of other institutions' next-generation cutting-edge models.
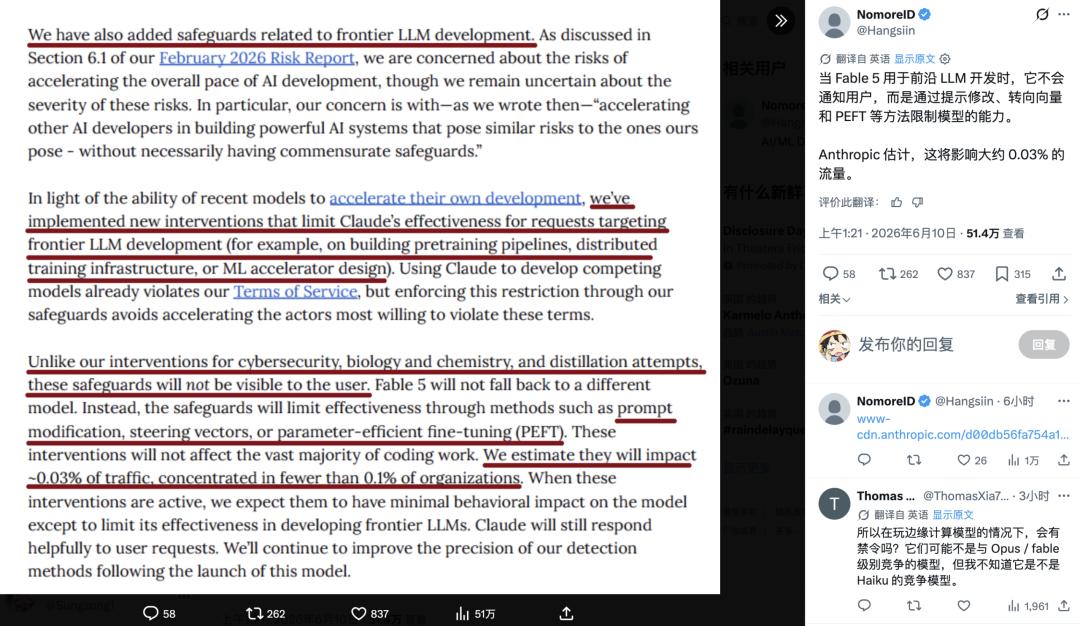
Unlike safety restrictions that switch to Opus 4.8 after being triggered, this type of protection will not directly prompt users but will lower Fable 5's performance on related tasks through prompt modifications, steering vectors, or PEFT. Some victims have already come forward to testify.
As of now, Claude Fable 5 is now available to users worldwide. Developers can invoke claude-fable-5 through the Claude API. The Claude API and pay-per-use Enterprise plans have been fully available since the release date.
Fable 5 and Mythos 5 are priced the same, at $10 per million input tokens and $50 per million output tokens. According to Anthropic, this is already less than half of the Claude Mythos Preview, but for high-intensity long tasks, the price is still not low.
AI has finally counted six fingers
Compared to the official blog, practical tests better illustrate where Fable 5 has strengthened. According to my practical tests, Fable 5 is now capable of recognizing six fingers.

Coincidentally, with the end of the college entrance examinations, we also took a national college entrance examination Chinese composition topic for it to practice. How should I put it? Overall, the writing style is relatively smooth and not "ordinary."

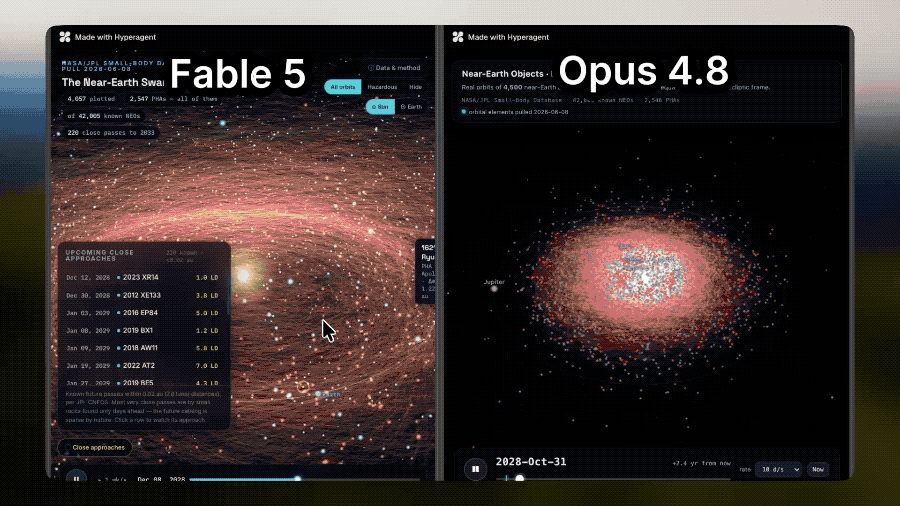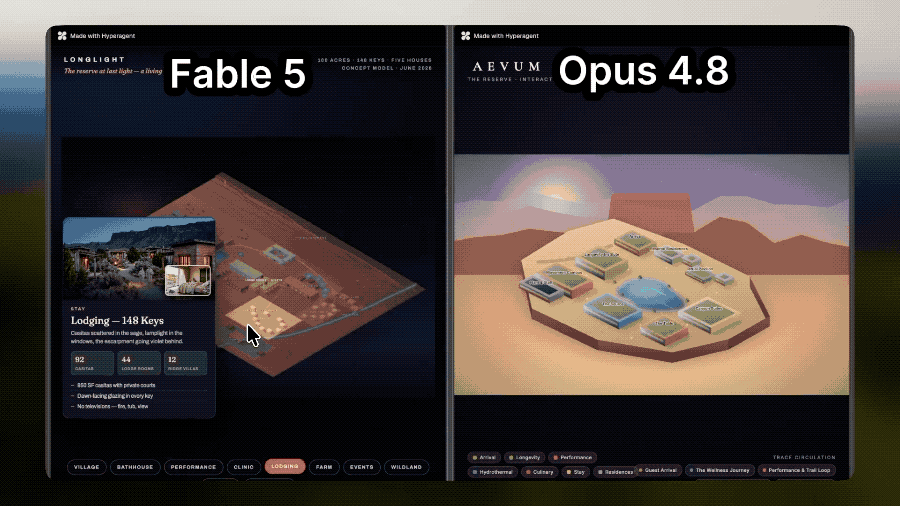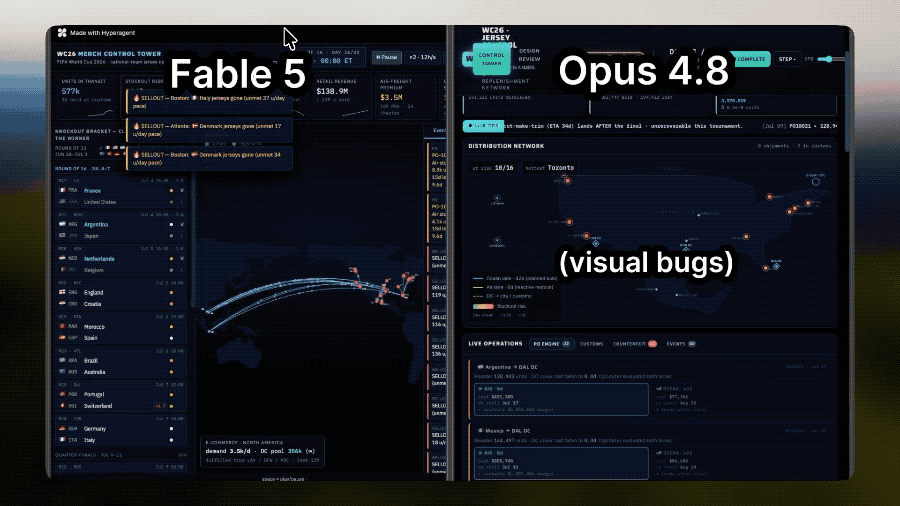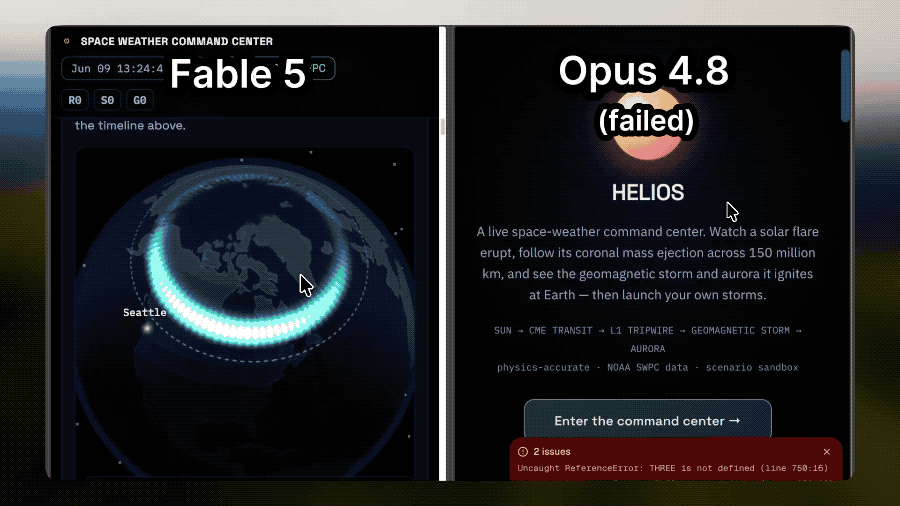
More specific comparisons can refer to @Hypergent's practical tests. In the asteroid visualization task, Fable 5 not only completed data extraction but also designed an interactive demonstration that included orbital trajectories and hovering details, enhancing information expression capabilities while ensuring performance.
In the fitness resort planning task, Fable 5 used GPT-Image-2 and Nano Banana to generate venue plans that better conform to practical usage logic, taking into account area connectivity, functional distribution, and flow of people, rather than simply placing buildings.

Fable 5 is able to combine astronomical phenomena with visual expression, demonstrating simulations of how solar flares affect auroras; while Opus 4.8 could not even load properly.
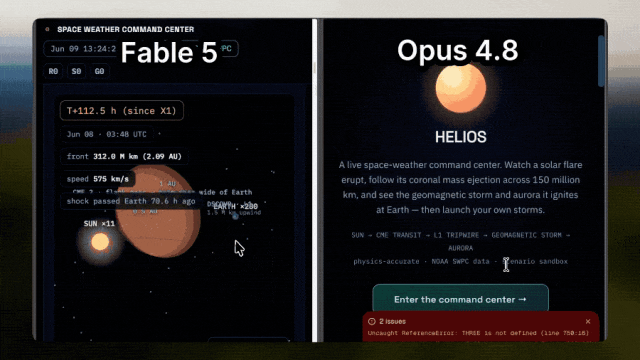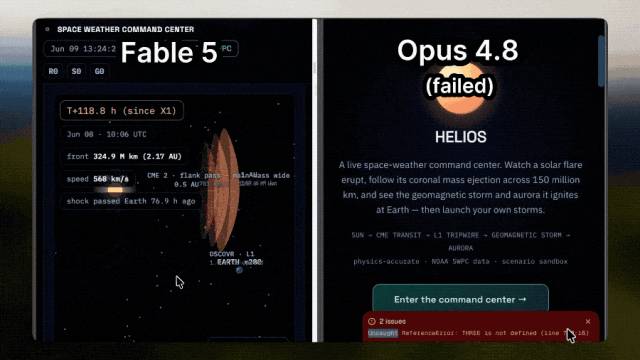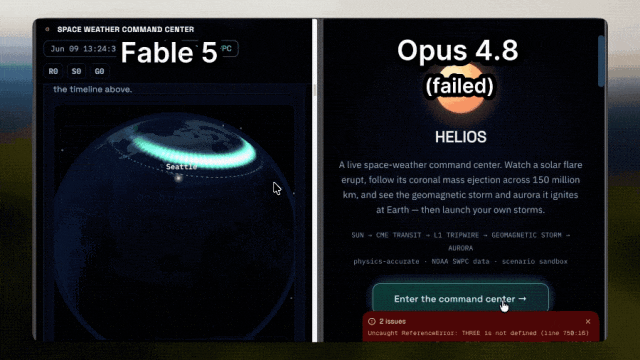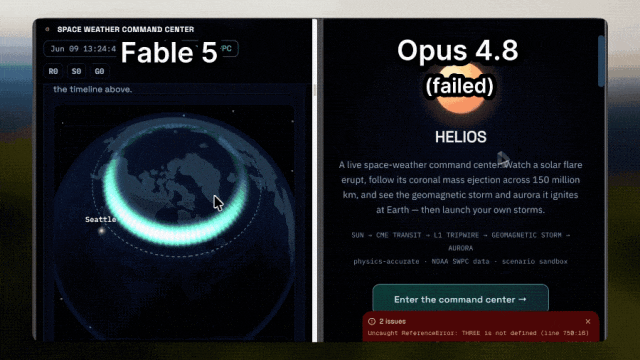
The former Tesla AI director and OpenAI co-founder Andrej Karpathy (who has now joined Anthropic) provides an evaluation that better reflects developers' sentiments.
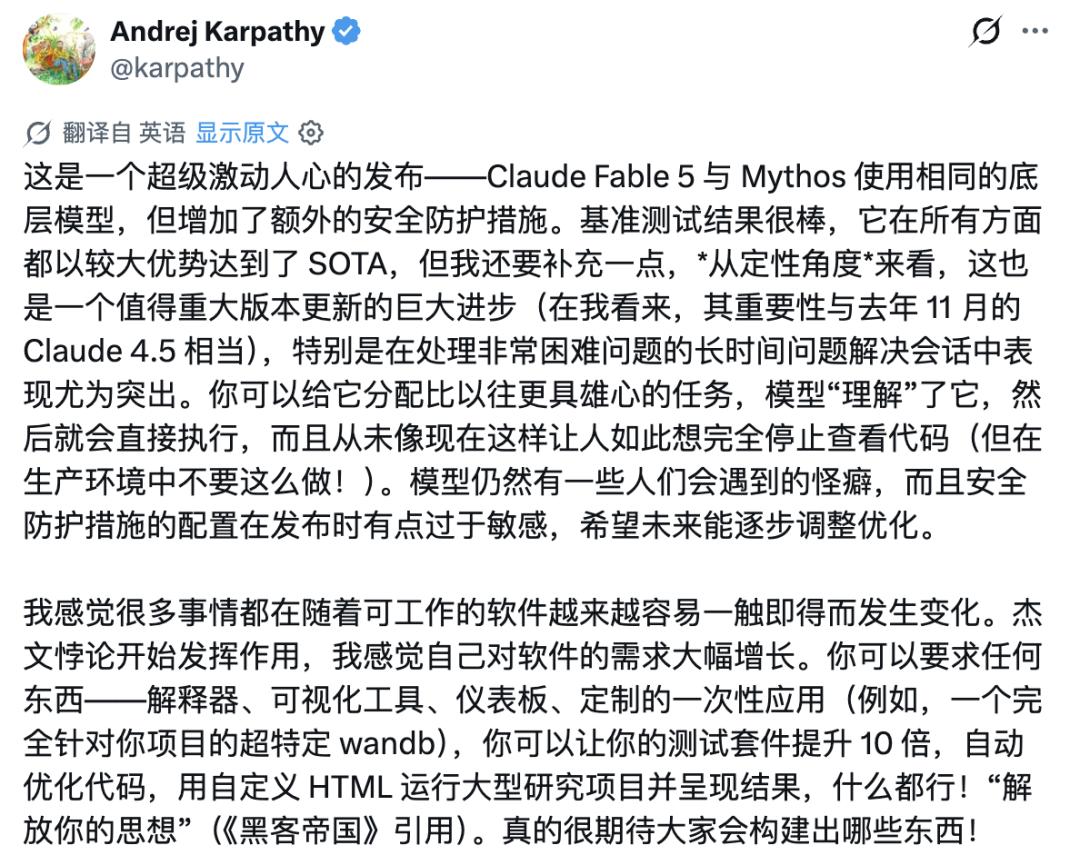
However, in terms of design aesthetics, humanity still holds a slight advantage at present.
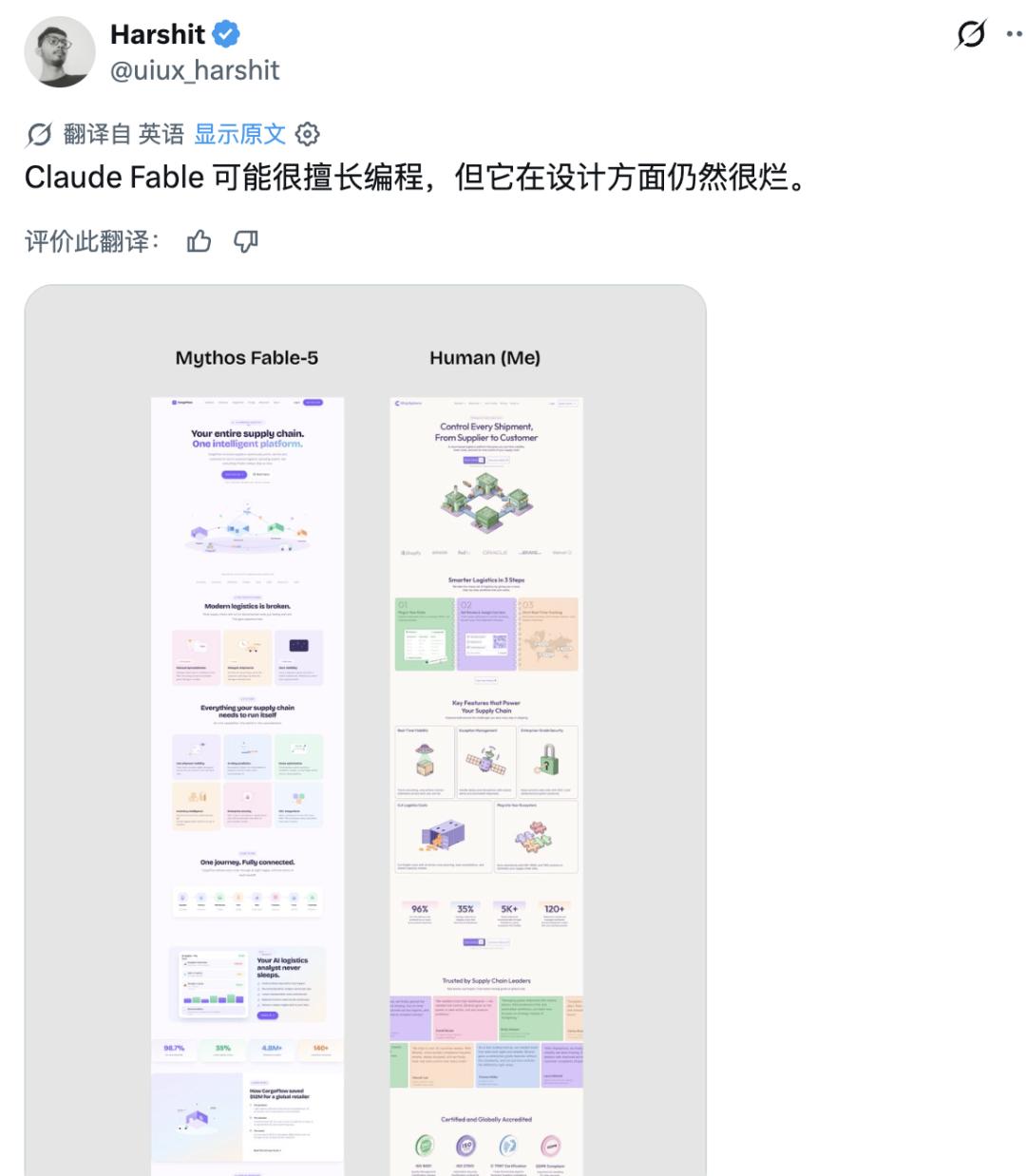
Wharton School professor Ethan Mollick's practical tests better reflect the changes in Fable 5. After gaining early access, he focused on testing complex tasks such as games, maps, and research tools.
Among them, the most representative is an isochronous map project. Mollick asked Fable 5 to construct an interactive map based on real traffic data, showing the accessibility ranges of different cities within a certain time frame. The model then called multiple agents to collect flight, railway, and road data, while completing code writing and testing, continuously correcting results based on feedback.
Mollick also had Fable 5 develop a research tool called Concord. The model first generated a 19-page design document and then worked continuously for 9.5 hours before finally completing the software development used for analyzing open research data and calibrating the judgments of humans and AI.
Practical tests also revealed significant problems. Mollick believes that Fable 5 will still make mistakes and omissions, requiring manual checking and refinement. At the same time, the token consumption from long tasks is very high, and Fable 5's price is significantly higher than Opus 4.8. Once put into a production environment, costs may become the biggest real challenge.
High-intensity long task capabilities will ultimately reflect on usage costs. As a Pro user of a $20 plan, I found that I quickly exhausted my quota by simply running a few tasks.
Moreover, the Claude client indicates "Fable 5 included until June 22." As previously mentioned, according to Anthropic's arrangement, after the free inclusion window ends, Fable 5 will be removed from certain subscription plans, and continued use will require consuming usage credits.
In the past, users paid a relatively inexpensive monthly fee to enjoy access to some of the strongest intelligence in the world. The subscription model obscured real costs and allowed ordinary individuals to stand on the same starting line as some giants at certain moments.
With the arrival of token billing, everything will change.
AI will transition from a service that resembles a monthly subscription to a production material consumed based on usage. The strongest models are also turning into more expensive, more finely priced production tools.
Some individuals may not care much about costs, such as letting Fable 5 perform a 24-hour long chain task, reconstructing 50 million lines of code, independently developing a complete application, continuously running research projects, and repeatedly testing and modifying results.
But more ordinary users will subconsciously weigh before each invocation: is this issue worth spending tokens on? Is this task worth handing over to the strongest model? After this attempt fails, should I ask it to try again?
The worst news is this. AI has not weakened. On the contrary, it is becoming stronger at an unprecedented pace, strong enough to independently complete more and more cognitive tasks that originally belonged to humans.
At the same time, the ticket to obtain such capabilities is continuously rising. The information gap between ordinary people and advanced productivity, which was just narrowed by large models, may reopen due to the expensive token billing.
Anthropic, as well as other manufacturers like OpenAI in the future, will likely find it difficult to be exceptions. The stronger the cutting-edge model, the higher the training and inference costs, especially considering that both of these AI companies are currently vying for listings and must prove to the capital market that they can not only train stronger models but also turn model capabilities into sustainable revenue.
Therefore, rather than saying that the release of Fable 5 is an upgrade of the model, it is better to say that it is a prelude to a complete adjustment of the AI subscription system. If the window of universal access to AI is starting its countdown, then this will certainly not be the best news.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








