Original Title: "Opus 4.7 Never Intended to Be 'The Strongest Model': Everyone Praising Claude's Speed Can't Keep Up with Anthropic's Rhythm Now"
Original Source: Silicon Star Pro
On April 16, 2026, Anthropic officially released Claude Opus 4.7, just over two months after the previous generation Opus 4.6 was released.
After a recent flurry of intense and crazy product and model updates, launching a new model by Anthropic naturally gives the impression of playing a trump card. You must have seen many first-hand model reports summarizing, with everyone calling Opus 4.7 'the strongest model,' and once again 'humanity is done,' 'job loss warning,' and so on trending.
But we should still take a look at what Anthropic itself has released.
The tone of this release is actually quite unusual.
Anthropic directly stated in the announcement: the capabilities of Opus 4.7 are inferior to Claude Mythos Preview—which is only open to a few partners like Apple, Google, Microsoft, and Nvidia, and not available to ordinary developers and users.
Meanwhile, what’s even more noteworthy than this remark is that it is not only weaker than the legendary Mythos; it is actually weaker than the previous generation model in several key capabilities.
An abnormal number in the score sheet for Opus 4.7: the long-context benchmark MRCR v2 @1M plummeted from 78.3% in Opus 4.6 to 32.2%, a drop of 46 percentage points.
It is rare for a flagship model upgrade to cut its flagship capabilities in half.
Moreover, this is a choice it actively made.
So, while everyone continues to thoughtlessly praise every model as 'the strongest,' they are actually no longer keeping up with Anthropic’s own rhythm!
It doesn’t even care to address this car wash issue.
Opus 4.7 is a release that fundamentally didn’t aim to become 'the strongest model'; it is a release with clear trade-offs, a 'precise scalpel' type release, different from various release strategies of previous leading model manufacturers, and also reflects the new direction that leading manufacturers are collectively shifting towards after clearly feeling that the 'great leap forward' of the model itself is no longer sustainable—Anthropic is now somewhat aligning with the release strategies of companies like Apple and Microsoft at their very mature product commercialization stages.
This might be the truly important aspect of 4.7.
1. Programming Capability: Real Improvements Behind the Numbers
To better understand these changes, the best way is, naturally, to first take a close look at what was actually released this time.
Here is the complete summary of the information released with Opus 4.7—where improvements were made, where it fell short, what developers' first-hand feedback is, and whether migration is necessary.
Official Announcement: https://www.anthropic.com/news/claude-opus-4-7
The programming performance of Opus 4.7 is the main focus of this release.
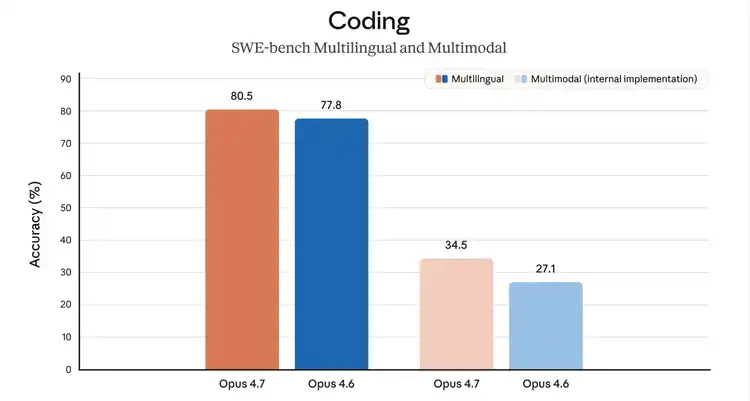
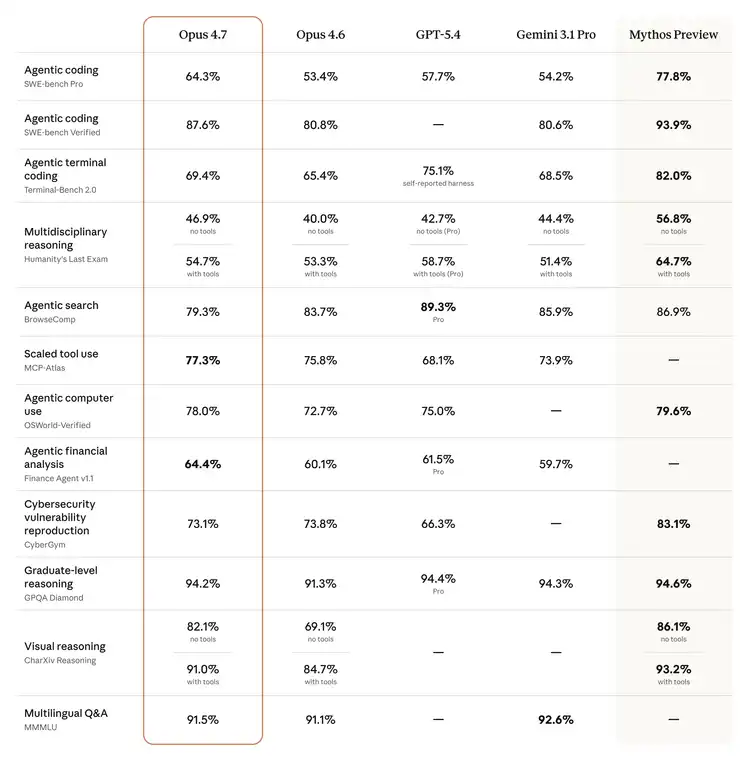
SWE-bench Verified (500 real GitHub issues, the model must write patches that can pass tests) rose from 80.8% in Opus 4.6 to 87.6%, an increase of nearly 7 percentage points, making it the top among currently publicly available models. Compared to Gemini 3.1 Pro's 80.6%, the gap is clear.
SWE-bench Pro is the more difficult version, covering a full engineering pipeline in four programming languages. Opus 4.7 jumped from 53.4% to 64.3%, an 11 percentage point increase. Compared to GPT-5.4's 57.7% and Gemini 3.1 Pro's 54.2%, Opus 4.7 clearly leads in this benchmark.
CursorBench is a practical benchmark from Cursor, specifically measuring model performance in real IDE environments. Opus 4.6 was at 58%, while Opus 4.7 jumped to 70%, a 12 percentage point improvement. Michael Truell, co-founder of Cursor, said in the official announcement: "This is a meaningful leap in capability, with stronger creative reasoning when solving difficult problems."
Partner Test Data:
· Rakuten: The number of production tasks solved by Opus 4.7 is three times that of Opus 4.6, with both code quality and testing quality ratings showing double-digit improvements.
· Factory: Task success rates improved by 10-15%, and instances of the model stopping mid-task significantly decreased.
· Cognition (the company behind Devin): The model "can work continuously for hours without disconnecting."
· CodeRabbit: Recall rate improved by over 10%, "slightly faster than GPT-5.4 xhigh mode."
· Bolt: In longer application building tasks, Opus 4.7 improved "by 10% in the best case compared to Opus 4.6, with no regression issues seen previously."
· Terminal-Bench 2.0: Opus 4.7 solved three tasks that no prior Claude model (or competitors) could handle, one of which required reasoning across complex multi-file codebases to fix a race condition.

These data points indicate one direction: Opus 4.7 shows significant improvement in complex programming tasks that involve long durations, cross-file operations, and maintaining contextual coherence. This is precisely the point that Opus 4.6 users complained the most about in the past two months—automatically giving up halfway through tasks and getting lost when encountering multi-file bugs.
2. Visual Capability: The Most Underestimated Improvement in This Release
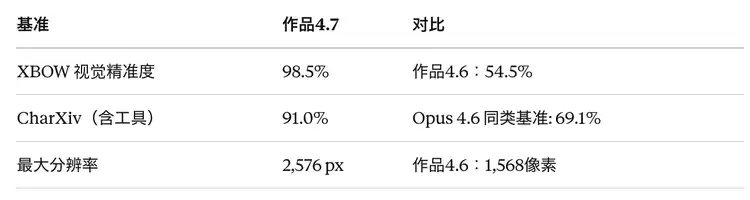
The visual accuracy benchmark XBOW jumped from 54.5% to 98.5%. This is not a gradual improvement, but a transformative leap.
Specific specification changes:
· The maximum image resolution improved from approximately 1.15 million pixels (long side 1,568 pixels) to approximately 3.75 million pixels (long side 2,576 pixels), more than three times that of the previous generation.
· The model coordinates correspond to actual pixels 1:1, eliminating the previous manual scaling calculations needed for computer use tasks.
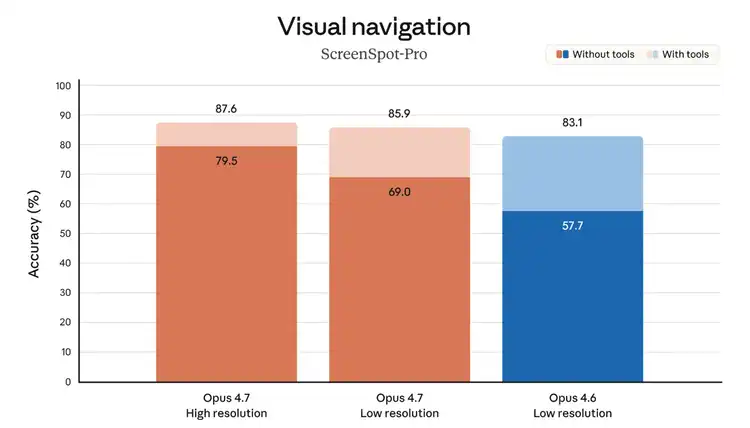
· CharXiv visual reasoning benchmark: 82.1% without tools, 91.0% with tools.
What real impact does this have in certain scenarios?
For the computer use product teams, this upgrade could be decisive. During the Opus 4.6 era, computer use was in a state of "able to do demos but dare not go into production"—the error rate was too high, making it unpredictable. An accuracy rate of 98.5% means that this feature has finally reached a reliable deployment threshold. Several tech blogs stated directly in their reviews: if you shelved computer use product plans due to the high error rate in Opus 4.6, 4.7 has cleared that obstacle.
First-hand feedback on Reddit (r/ClaudeAI): Some users mentioned, "The improvement in visual capabilities is crucial. I previously worked on many edge projects, trying to get the model to iterate and improve output in a visual feedback loop, but the results were consistently chaotic. I can’t wait to see how 4.7 handles this issue."
In addition to computer use, benefiting scenarios include: document scanning analysis (able to read smaller fonts and recognize finer chart details), screenshot understanding, dashboard applications, and complex PDF processing.
Cost issues to be aware of: Higher resolution images will consume more tokens. If your application scenario does not require high image detail, it is recommended to downsample before inputting.
3. The Biggest Setback: Long Context Failures
MRCR v2 @1M (one million token long context memory test):
· 4.6: 78.3%
· 4.7: 32.2%
A drop of 46 percentage points, falling from nearly 80% directly to one-third.
This type of drop is almost unprecedented in flagship model iterations. MRCR v2 is a capability that Anthropic touted heavily during the Opus 4.6 era—at that time, Anthropic's own words were, "a qualitative change occurred at a usable level of context for a model." By 4.7, that "qualitative change" has directly disappeared.
Why did this happen? The tokenizer has changed.
Opus 4.7 uses a new tokenizer, which generates approximately 1.0-1.35 times the token count for the same input text, with the specific multiple varying based on content type.
The direct chain reaction is:
· The nominal context window of 200K/1M is still there, but the amount of text that can fit has decreased.
· The actual token consumption of long task agent workflows has increased by approximately 35%.
· The pricing remains unchanged (input $5, output $25 per million tokens), but actual usage costs have risen.
A official statement from Anthropic claims that the new tokenizer "increases text processing efficiency," but benchmark data shows a significant setback in long context scenarios.
Search capabilities have also declined:
· BrowseComp (deep web information retrieval): Opus 4.6’s 83.7% → Opus 4.7’s 79.3%
· GPT-5.4 Pro scored 89.3% on this, Gemini 3.1 Pro scored 85.9%, and Opus 4.7 is currently at the bottom among the main competitors.
Search and long text are precisely the scenarios most commonly used by many enterprise users.
First-hand feedback from developers on Hacker News (post with 275 upvotes and 215 comments, source: HN discussion):
"I had to turn off adaptive thinking and manually set effort to max to get back to baseline performance. The statement 'it looks good in our internal evaluations' is no longer enough—all users are seeing the same problems." "4.7 no longer includes human-readable reasoning token summaries by default; you must add display: summarized in the API request to retrieve it."
These are all issues reflected by actual users. But this was also a choice actively made by Anthropic.
4. New Behavioral Features: Self-Verification and More Literal Instruction Following
There is a notable line in the official announcement of Opus 4.7: the model will verify its output before reporting results.
The tech team from Hex provided a specific case in testing: when data is missing, Opus 4.7 will report "data does not exist" truthfully, rather than providing a seemingly reasonable but actually fabricated answer—which was a pitfall that Opus 4.6 would fall into. The fintech platform Block commented on this: "It can detect its own logical errors in the planning stage, accelerating execution speed, showing a clear advancement over previous Claude models."
However, self-verification has brought about another related behavioral change: Opus 4.7 interprets instructions more literally.
This presents an important migration risk. If you have meticulously tuned prompts for Opus 4.6, 4.7 may not interpret implied meanings like 4.6 did, but will execute strictly according to the literal wording. Anthropic explicitly mentioned this in the official migration guide, suggesting that regression tests are performed on key prompts before going live with 4.7.
A practical reference number comes from Hex's CTO: the low effort tier of Opus 4.7 performs roughly equivalent to the medium effort tier of Opus 4.6.
5. Inference Control Mechanism: xhigh, Task Budgets, and /ultrareview
Something happened with Opus 4.6 that impacted user trust: on February 9, it switched to the adaptive thinking default mode, and on March 3, the official default inference depth for Claude Code was adjusted from max to medium, citing "balancing intelligence, latency, and cost." This was referred to by users as the "dumbing down door," with a GitHub post from a senior director at AMD widely shared in skepticism.
Opus 4.7’s response is to more explicitly hand over control of inference depth to users.
xhigh effort tier: A new level of reasoning intensity added, positioned between the original high and max. Claude Code has now updated all planned default levels to xhigh.
However, the developer community has a direct question about xhigh; a Reddit user stated, "Opus 4.6 defaulted to medium, while 4.7 defaults to xhigh. I want to know the considerations behind this decision because increasing the effort tier clearly leads to more token consumption."
In other words: What users see as a "restoration of control to the user" fix actually means that the default tier has been raised, which implies that the same task will consume more tokens. When combined with the tokenizer changes, this leads to a double cost increase.
Task budgets (in public testing): A token budget control mechanism aimed at long tasks. Developers set a total token budget (minimum 20K), and the model can see the remaining budget in real-time during execution, allocating resources accordingly to avoid stopping midway due to token overrun, as well as preventing unnecessary computational waste.
Claude Code added /ultrareview command: A dedicated code review session, running a deep review focused on bug checking and design issues, Pro and Max users receive 3 free uses per month.
Auto mode open to Max users: Previously only available in the Enterprise plan, Max users can now also use it. Claude, in auto mode, can make decisions autonomously, reducing the frequency of mid-task user confirmations. As Boris Cherny, head of the Claude Code team, put it: "Give Claude a task, let it run, and come back to verified results."
6. Scoring Overview: Where It Won, Where It Lost
Here are the main benchmark data that have been released so far (source: Anthropic official system card and partner evaluations).
Programming and Engineering (Opus 4.7 Leads)
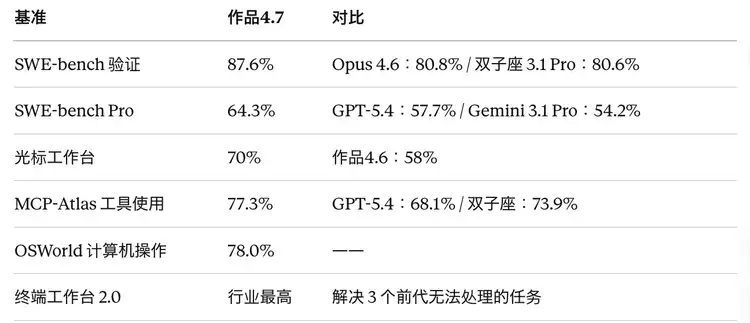
Visual and Multimodal (Opus 4.7 Significantly Leads)
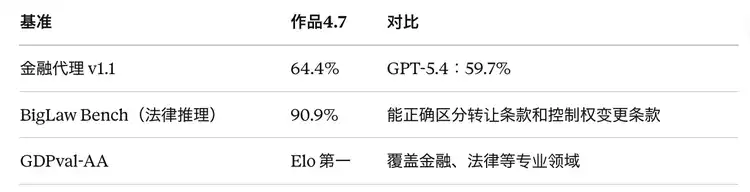
Knowledge Work (Opus 4.7 Leads)
Comprehensive Evaluation (Opus 4.7 Clearly Upgraded)

General Reasoning (Three are Basically Equal)

This benchmark has become saturated, no longer serving as an effective competitive dividing line.
Research Tasks (GPT-5.4 Leads, Opus 4.7 Declines)

Long Context (Opus 4.7 Greatly Declines)

Summary of Selection Logic: In programming, engineering agents, visual capabilities, and financial legal knowledge work, Opus 4.7 has clear advantages; in research-intensive tasks and open web retrieval, GPT-5.4 is stronger; in long context scenarios, Opus 4.7 is significantly worse than its predecessor, and this is the most alarming point.
7. Safety Barriers: The Paving Stone for Mythos
This section is easily overlooked as a "routine safety disclaimer" in a press release, but it is key to understanding Anthropic's current strategy.
On April 7, Anthropic announced Project Glasswing: opening Claude Mythos Preview to nine partners including Apple, Google, Microsoft, Nvidia, Amazon, Cisco, CrowdStrike, JPMorgan Chase, and Broadcom, specifically for defensive cybersecurity scenarios.
Mythos is Anthropic's most capable model to date; according to The Hacker News, it can autonomously discover zero-day vulnerabilities, identifying thousands of previously unknown flaws in major operating systems and browsers. However, due to this capability, it is also deemed to have significant abuse risks, hence not publicly released.
Opus 4.7 is the first test sample along this line. Anthropic actively reduced the model’s cybersecurity attack capabilities during the training phase (while attempting to retain defense capabilities) and launched a real-time barrier system that automatically detects and intercepts high-risk cybersecurity requests. The original announcement stated: "We will learn whether this barrier is effective through the actual deployment of Opus 4.7 before deciding whether to extend it to models at the Mythos level."
In other words, every developer using Opus 4.7 is helping Anthropic calibrate the security barrier's boundaries.
Gizmodo's evaluation: This release utilized a "bold marketing strategy—actively promoting its new model's 'general capability is inferior to other options'," which is extremely rare in flagship releases.
Securities professionals needing to use Opus 4.7 for legitimate penetration testing, vulnerability research, or red team testing must apply to join the Cyber Verification Program.
8. Pricing and Migration: Nominally Unchanged, Actual Costs Increased
Pricing: Input $5/million tokens, output $25/million tokens, the same as Opus 4.6. The API model ID is claude-opus-4-7. Available platforms include Claude API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, and GitHub Copilot has also been launched simultaneously.
But as mentioned earlier, the tokenizer change results in approximately 1.0-1.35 times the token count for the same input, compounded by higher default effort settings, resulting in practical costs potentially being 2-3 times that of Opus 4.6 under the same settings for long task agent workflows.
Anthropic has also shortened the cache TTL (Time to Live) for Claude Code from one hour to five minutes—meaning if you leave the computer for more than five minutes and then return, the context cache will expire, requiring reloading and thus consuming tokens more quickly. Many users in the Reddit community have already complained that "the quota burns faster than a waterfall."
Destructive changes list for existing Opus 4.6 users:
1. Extended Thinking Budgets parameter has been removed; inputs will return a 400 error, and you must switch to adaptive thinking mode.
2. Sampling parameters such as temperature, top_p, and top_k have been removed; you need to use prompting to control output behavior.
3. Stricter literal instruction following—prompts tuned for Opus 4.6 need to be retested and cannot simply be switched by changing the model ID during deployment.
4. Tokenizer changes result in variations in token counting. It is recommended to run samples on real traffic before full migration.
5. Default output no longer includes reasoning token summaries; you need to explicitly set display: summarized to retrieve them.
Practical suggestion: Anthropic's official migration guide recommends running Opus 4.7 with representative production traffic before formally switching to compare token consumption and task quality before making a decision.
Wielding a precise scalpel is the most terrifying.
Opus 4.7 is an upgrade with a clear focus and also comes at a notable cost. Moreover, these are all design choices made by Anthropic, and to a large extent, you must pay for it.
The advancements of this model:
· SWE-bench Verified at 87.6%, SWE-bench Pro at 64.3%, CursorBench at 70%, Rakuten’s threefold production tasks—these are perceived programming capability improvements in production environments.
· Reconstruction of visual capabilities (XBOW 54.5% → 98.5%, resolution tripling, pixel 1:1 correspondence) has finally established a reliable deployment threshold for computer use.
· xhigh tier, task budgets, /ultrareview are explicit responses to the "dumbing down door."
· BigLaw 90.9%, Finance Agent 64.4%, clear lead in specialized knowledge work in finance and law.
What has been given up:
· MRCR v2 @1M dropping from 78.3% to 32.2%, nearly halving long-context capabilities.
· BrowseComp falling from 83.7% to 79.3%, search capabilities being surpassed by both GPT-5.4 and Gemini 3.1 Pro.
· Tokenizer changes + raising default effort + shortened cache TTL = triple hidden price increase.
· Mythos being held back means that Anthropic still possesses something stronger in hand but cannot release it.
The most real aspect of this release is not 'the strongest model' nor 'the strongest public model,' but rather: an iteration with clear trade-offs.
The latest news states that Claude Code's annual revenue reached 2.5 billion dollars in February. Opus 4.7 is the next bet along this line.
Programming and visual capabilities are additive, while long-term context and search capabilities are subtractive. Pricing remains nominally unchanged, but the bills are increasing. Anthropic is balancing with Opus 4.7—repairing the trust damage left from Opus 4.6 while also conducting practical drills for safety barriers in preparation for a broader future opening of Mythos-level models. More importantly, it aims to take full advantage of its leading position today, transforming user appreciation for its products into an irreplaceable inertia towards each successive generation of products, even with flaws, and building a user stickiness that companies like Apple have only entered in their mature phase, along with economically valuable ecosystems.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






