AI products are transitioning from "tools" to "relationships," and people need to decide what kind of relationships to establish.
Compiled by: Moonshot
Source: Geek Park
The year 2025 will be the year when Agents hit the accelerator.
From the astonishment triggered by DeepSeek at the beginning of the year to the successive appearances of GPT-4o and Claude 3.5, the boundaries of large models have been rewritten time and again. However, what truly tightened the nerves of the AI industry chain is not the iteration of model performance, but the emergence of Agents.
The explosive popularity of products like Manus and Devin reaffirms a consensus: large models will no longer just be tools; they are to become self-scheduling intelligent agents.
Thus, Agents have become the second wave of consensus formation in the global tech circle, following large models.
From the strategic restructuring of tech giants to the rapid follow-up in the entrepreneurial arena, Agents are becoming the next direction for widespread investment. However, amidst the intensive emergence of consumer-facing products and the fervor of developers, projects that truly establish a user value closed loop are rare, with more and more products falling into the anxiety of "applying old demands to new technologies."
After the heat wave, the market has returned to calm: is Agent truly a paradigm reconstruction, or just a new packaging? Does the so-called distinction between "general" and "vertical" paths really bring sustainable market space? And behind the "new entry," is it an evolution of interaction methods or a projection of the old world?
Delving deeper into these questions, we may find that the real threshold for Agents may not lie in model capabilities, but in the underlying infrastructure they depend on. From controllable operating environments to memory systems, context awareness, and tool invocation, the absence of each foundational module is the greatest resistance for Agents to transition from demonstration to practicality.
These underlying engineering issues constitute the biggest obstacle for Agents to move from "trendy toys" to "productivity tools," and they are precisely the most certain and valuable entrepreneurial blue ocean at present.
In this phase of supply overflow and unclear demand, we want to use this dialogue to answer an increasingly urgent question: where do the true problems and opportunities of Agents lie?
In this in-depth discussion, we have invited Li Guangmi, founder of Shixiang Technology, and Zhong Kaiqi, AI Research Lead at Shixiang Technology, both practitioners who will dissect the true problems and opportunities of Agents from multiple dimensions, including product forms, technical paths, business models, user experiences, and even infrastructure construction.
We will follow their thoughts to explore where the real opportunities for startups lie at a table surrounded by tech giants; how a pragmatic growth path from "Copilot" to "Agent" is being validated step by step; and why the seemingly vertical field of Coding is viewed as a "value high ground" and "key indicator" on the path to AGI.
Ultimately, this conversation will push towards a further future, glimpsing the new collaborative relationship between humans and Agents, as well as the core challenges and infinite opportunities faced in building the next generation of intelligent infrastructure.
Key Points
The best in the general Agent field is "Model as Agent."
When developing Agents, it is not necessary to "start with the end in mind." One can begin with a Copilot and gradually transition to a fully automated Agent. In this process, collect user data, enhance user experience, occupy user mindset, and then slowly transform.
AGI may first be realized in a Coding environment because this environment is the simplest and can exercise AI's core capabilities. Coding is the "universal tool" in this world; with it, AI can build and create. Coding could potentially capture 90% of the value in the entire large model industry phase.
AI Native products are not just for human use; they must also serve AI. A true AI Native product should have a built-in mechanism to serve both AI and humans.
Today's AI products are transitioning from "tools" to "relationships." People do not form relationships with tools, but they will with an AI that has memory, understands them, and can resonate with them.
The following is a summary from the live broadcast of "Tonight's Tech Talk," organized by Geek Park.
01 Amidst the Wave, Which Agent Products Have Emerged?
Zhang Peng: Recently, everyone has been discussing Agents, considering it an important topic at this stage and a rare development opportunity for startups.
I see that Shixiang Technology has conducted in-depth research on the Agent system and has experienced and analyzed many related products. I would like to hear from both of you about which recent Agent-related products have left a deep impression on you and why.
Li Guangmi: The two that impressed me the most are: one is Anthropic's Claude in terms of programming capabilities, and the other is OpenAI's ChatGPT with its Deep Research feature.
Regarding Claude, it is mainly its programming ability. I have a viewpoint: Coding is the most critical prior indicator for measuring AGI. If AI cannot scale and perform end-to-end software application development, progress in other areas will also be slow. We must first achieve strong ASI (Artificial Superintelligence) in the Coding environment before accelerating in other fields. In other words, we first achieve AGI in the digital environment and then expand to other areas.

The world's first AI programmer Devin | Source: Cognition Labs
Regarding Deep Research, it has been very helpful to me; I use it almost every day. It is essentially a search Agent that helps me retrieve a large amount of web pages and information, providing a great experience and significantly expanding my research space.
Zhang Peng: Kaiqi, from your perspective, which products have left a deep impression on you?
Zhong Kaiqi (Cage): I can share my thinking model for observing and using Agents, and then introduce one or two representative products under each category.
First, people often ask: general Agent or vertical Agent? We believe that the best in the general Agent field is "Model as Agent." For example, the Deep Research mentioned by Guangmi and OpenAI's newly released o3 model are standard examples of "Model as Agent." They integrate all components of an Agent—large language models (LLM), context, tool use, and environment—into one and conduct end-to-end reinforcement learning training. The result after training is that various Agents can perform information retrieval tasks.
So, my "bold statement" is that the demand for general Agents is basically just information retrieval and light coding, and GPT-4o has already done very well in this regard. Therefore, the general Agent market is basically the main battlefield for large model companies, making it difficult for startups to grow by merely serving general needs.
The startups that have impressed me are mostly focused on vertical fields.
If we first talk about the ToB vertical field, we can compare human work to front-end work and back-end work.
The characteristics of back-end work are high repetition and high demand for concurrency, usually with a long SOP (Standard Operating Procedure), where many tasks are very suitable for AI Agents to execute one-on-one and are suitable for reinforcement learning in a relatively large exploration space. A representative example I want to share is some startups focused on AI for Science, which are working on Multi-agent systems.
In this system, various research tasks are included, such as literature retrieval, experiment planning, predicting cutting-edge progress, and data analysis. Its characteristic is that it is no longer a single Agent like Deep Research, but a very complex system capable of achieving higher resolution for research systems. It has a very interesting feature called "Contradiction Finding," which can handle adversarial tasks, such as discovering contradictions between two top journal papers. This represents a very interesting paradigm in research-oriented Agents.
Front-end work often involves interacting with people and requires outreach. Currently, a suitable option is voice Agents, such as nurse follow-up calls in the medical field, recruitment, logistics communication, etc.
Here, I want to share a company called HappyRobot, which has found a seemingly small scenario, specifically doing phone communication in the logistics and supply chain field. For example, if a truck driver encounters a problem, or when the goods arrive, the Agent can quickly call him. This showcases a unique capability of AI Agents: 24/7 uninterrupted response and quick reaction. This is sufficient for most logistics needs.
In addition to these two categories, there are also some more unique examples, such as Coding Agents.
02 From Copilot to Agent, Is There a More Pragmatic Growth Path?
Zhong Kaiqi: In the field of code development, there has been a recent surge of entrepreneurial enthusiasm, with a great example being Cursor. The release of Cursor 1.0 has essentially transformed what originally seemed like a Copilot product into a fully-fledged Agent product. It can operate asynchronously in the background and has memory capabilities, which aligns with our vision of an Agent.
The comparison with Devin is quite interesting, and it inspires us: developing an Agent does not necessarily have to "start with the end in mind." One can begin with a Copilot and gradually transition to a fully automated Agent. In this process, collect user data, enhance user experience, occupy user mindset, and then slowly transform. A company doing well domestically is Minus AI, which also started with a Copilot form for its earliest product.
Finally, I will also use the "environment" thinking model to distinguish different Agents. For example, Manus operates in a virtual machine environment, Devin in a browser, flowith in a notebook, SheetZero in a spreadsheet, and Lovart in a canvas, etc. This "environment" corresponds to the definition of environment in reinforcement learning, which is also a classification method worth referencing.

flowith developed by a domestic startup | Source: flowith
Zhang Peng: Let's dive deeper into the example of Cursor. What is the technology stack and growth path behind it?
Zhong Kaiqi (Cage): The example of autonomous driving is quite interesting; even today, Tesla does not dare to remove the steering wheel, brakes, and accelerator. This indicates that AI has not yet fully surpassed humans in many critical decision-making areas. As long as AI's capabilities are similar to those of humans, some key decisions will definitely require human intervention. This is precisely what Cursor understood clearly from the beginning.
Thus, the feature they initially focused on was one of the most needed functions for humans: autocompletion. They made this function trigger with the Tab key, and with models like Claude 3.5 coming out, Cursor improved the accuracy of Tab to over 90%. At this level of accuracy, I can use it continuously 5 to 10 times in a task flow, creating a flow state experience. This is the first phase of Cursor as a Copilot.
In the second phase, they developed the code refactoring function. Both Devin and Cursor aimed to meet this demand, but Cursor did it more cleverly. It opens a dialog box, and when I input a requirement, it can initiate a parallel modification mode outside the file to refactor the code.
When this feature first came out, its accuracy was not high, but because users expected it to be a Copilot, everyone could accept it. Moreover, they accurately predicted that the model's coding capabilities would rapidly improve. So, they polished the product features while waiting for the model's capabilities to enhance, and the Agent's capabilities emerged smoothly.
The third step is the Cursor state we see today, a relatively end-to-end Agent that operates in the background. It has a sandbox-like environment behind it; I can even assign tasks I don't want to do to it while at work, and it can use my computing resources to complete them in the background, allowing me to focus on my core tasks that I want to do the most.
Finally, it informs me of the results in an asynchronous interaction format, like sending an email or a message on Feishu. This process smoothly realizes the transformation from Copilot to Autopilot (or Agent).
The key is to grasp human interaction psychology, making users more willing to accept synchronous interactions from the start, which allows for the collection of a large amount of user data and feedback.
03 Why is Coding the "Key Testing Ground" for AGI?
Zhang Peng: Guangmi just mentioned that "Coding is the key to AGI; if ASI (superintelligence) cannot be achieved in this field, it will be difficult in other areas." Why is that?
Li Guangmi: There are several logical points. First, code data is the cleanest, easiest to close the loop, and the results are verifiable. I have a hypothesis that chatbots may not have a data flywheel (a feedback loop mechanism that continuously optimizes AI models by collecting data from interactions or processes, leading to better results and more valuable data). However, the coding field has the opportunity to develop a data flywheel because it can undergo multiple rounds of reinforcement learning, and code is the key environment for running multiple rounds of reinforcement learning.
On one hand, I understand code as a programming tool, but I prefer to see it as an environment for achieving AGI. AGI may first be realized in this environment because it is the simplest, and it can exercise AI's core capabilities. If AI cannot even perform end-to-end application software development, it will be even more challenging in other fields. If it cannot replace basic software development tasks on a large scale in the near future, it will also be difficult in other areas.
Moreover, as coding capabilities improve, the model's instruction-following abilities will also enhance. For example, when handling long prompts, Claude performs noticeably better, and we speculate that this is logically related to its coding capabilities.
Another point is that I believe future AGI will first be realized in the digital world. In the next two years, Agents will be able to perform almost all tasks that humans do on phones and computers. On one hand, they can complete tasks through simple coding; if that doesn't work, they can also invoke other virtual tools. Therefore, achieving AGI in the digital world first, allowing it to run relatively fast, is a significant logic.
04 How to Determine a Good Agent?
Zhang Peng: Coding is the "universal tool" in this world; with it, AI can build and create. Moreover, the programming field is relatively structured, making it suitable for AI to perform. When evaluating the quality of an Agent, aside from user experience, what perspectives do you consider when assessing an Agent's potential?
Zhong Kaiqi (Cage): A good Agent must first have an environment to help build a data flywheel, and the data itself must be verifiable.
Recently, researchers at Anthropic have frequently mentioned a term called RLVR (Reinforcement Learning from Verifiable Reward), where the "V" refers to verifiable rewards. Code and mathematics are very standard verifiable fields; after completing a task, the correctness can be immediately verified, naturally establishing a data flywheel.
The working mechanism of the data flywheel | Source: NVIDIA
Therefore, building an Agent product requires creating such an environment. In this environment, the success or failure of users executing tasks is not important because current Agents will definitely fail. The key is that during failures, it can collect signal data rather than noise data to guide the optimization of the product itself. This data can even serve as cold start data for the reinforcement learning environment.
Second, whether the product is sufficiently "Agent Native." This means that when designing the product, one must consider the needs of both humans and Agents. A typical example is The Browser Company; why did they want to create a new browser? Because the previous Arc was purely designed to enhance human user efficiency. Their new browser, however, includes many new features that can be used by AI Agents in the future. When the underlying design logic of the product changes, it becomes very important.
From the results perspective, objective evaluation is also crucial.
Task completion rate + success rate: First, the task must be able to run to completion so that users can at least receive feedback. Secondly, there is the success rate. For a 10-step task, if the accuracy of each step is 90%, the final success rate is only 35%. Therefore, it is essential to optimize the connections between each step. Currently, a passing line in the industry might be a success rate of over 50%.
Cost and efficiency: This includes computational costs (token cost) and user time costs. If GPT-4o takes 3 minutes to run a task while another Agent takes 30 minutes, this is a significant burden for users. Moreover, the computational consumption during those 30 minutes is enormous, which will affect the scale effect.
User metrics: The most typical is user stickiness. After users try it out, are they willing to use it repeatedly? Metrics such as daily active users/monthly active users (DAU/MAU) ratio, next-month retention rate, and payment rate are fundamental indicators to avoid the company experiencing "false prosperity" (five minutes of fame).
Li Guangmi: I would like to add another perspective: the degree of matching between the Agent and current model capabilities. Today, 80% of an Agent's capabilities depend on the model engine. For example, when GPT reached 3.5, the general paradigm of multi-turn dialogue emerged, making the chatbot product form feasible. The rise of Cursor is also because the model has developed to the level of Claude 3.5, enabling its code completion capabilities.
For instance, Devin came out a bit too early, so the founding team's understanding of the boundaries of model capabilities is very important. They need to be clear about where the model can reach today and in the next six months, as this is closely related to the goals that the Agent can achieve.
Zhang Peng: What does it mean for a product to be "AI Native"? I believe that AI Native products are not just for human use; they must also serve AI.
In other words, if a product does not have reasonable data for debugging and does not build for the future working environment of AI, it merely treats AI as a tool for cost reduction and efficiency enhancement. Such products have limited vitality and can easily be overwhelmed by technological waves. A truly AI Native product should have a built-in mechanism to serve both AI and humans. Simply put, when AI serves users, are users also serving AI?
Zhong Kaiqi (Cage): I really like this concept. The data for Agents does not exist in the real world; no one will break down their thought process step by step when completing a task. So what can be done? One method is to find professional annotation companies, and another is to leverage users to capture their real usage patterns and the operational processes of the Agent itself.
Zhang Peng: If we want to use Agents to have humans "feed" data to AI, what kinds of tasks are the most valuable?
Zhong Kaiqi (Cage): Rather than thinking about using data to serve AI, it is better to consider what strengths AI has that should be amplified. For example, in scientific research, before AlphaGo, humans thought that Go and mathematics were the most difficult. However, after using reinforcement learning, it was found that these were actually the simplest for AI. The same applies to the scientific field; it has been a long time since a scholar could master every corner of each discipline, but AI can. Therefore, I believe that tasks like scientific research are very difficult for humans but may not be difficult for AI. Precisely for this reason, we need to find more data and services to support it. Such tasks have a higher return than most tasks and are more verifiable. In the future, it may even involve humans helping AI "shake test tubes" and then telling AI whether the results are right or wrong, helping AI illuminate the technology tree together.
Li Guangmi: The initial data cold start is necessary. Creating an Agent is like starting a startup; the founder must engage in the cold start personally. Next, building the environment is crucial, as it determines the direction the Agent will take. After that, establishing a reward system becomes even more important. I believe that the environment and rewards are two key factors. On this basis, the entrepreneur behind the Agent can effectively act as the "CEO" of this Agent. Today, AI can already write code that humans cannot understand but can run; we don't necessarily need to comprehend the end-to-end logic of reinforcement learning, as long as we set up the environment and establish the rewards.
05 Where Will the Business Model of Agents Go?
Zhang Peng: Recently, we have seen many Agents in the ToB field, especially in the United States. Have there been any changes in their business models and growth patterns? Or are there new models emerging?
Zhong Kaiqi (Cage): The biggest characteristic now is that more and more products are entering from the C-end and being used in organizations from the bottom up. The most typical example is Cursor. Besides it, there are many AI Agents or Copilot products that people are willing to use themselves first. This is no longer the traditional SaaS model that requires securing the CIO and signing one-on-one contracts; at least, the first step is not like that.
Another interesting product is OpenEvidence, which targets the group of doctors. They first engage the doctor community and then gradually embed advertisements for medical devices and drugs. These businesses do not need to negotiate with hospitals from the start, as discussions with hospitals are very slow. The key to AI entrepreneurship is speed; relying solely on a technological moat is not enough; growth needs to happen through this bottom-up approach.

AI medical unicorn OpenEvidence | Source: OpenEvidence
Regarding business models, there is a trend of gradually shifting from cost-based pricing to value-based pricing.
Cost-based: This is like traditional cloud services, adding a layer of software value on top of CPU/GPU costs.
Pay-per-use: In the Agent space, one model is charging per "action." For example, the logistics Agent I mentioned earlier charges a few cents for making a phone call to a truck driver.
Workflow-based charging: A higher level of abstraction is charging based on "workflow," such as completing an entire logistics order. This is further from the cost side and closer to the value side because it genuinely participates in the work. However, this requires a relatively convergent scenario.
Pay for results: Moving up, there is payment based on "results." Because the success rate of Agents is not high, users want to pay for successful outcomes. This requires Agent companies to have a high level of product refinement capability.
Pay for the Agent itself: In the future, it may be possible to pay directly for the "Agent." For example, a company called Hippocratic AI is developing AI nurses. Hiring a human nurse in the U.S. costs about $40 per hour, while their AI nurse only costs $9 to $10 per hour, reducing costs by three-quarters. In a market like the U.S., where labor is expensive, this is very reasonable. If Agents can perform even better in the future, I might even give them bonuses or year-end rewards. These are all innovations in business models.
Li Guangmi: What we look forward to most is the value-based pricing model. For example, if Manus AI creates a website, is that worth $300? If it creates an application, is that worth $50,000? However, today, the task value is still difficult to price. Establishing a good measurement and pricing method is worth exploring for entrepreneurs.
Additionally, as Cage just mentioned about paying for Agents, it’s similar to how companies sign contracts with employees. In the future, when we hire an Agent, do we need to give it an "ID card"? Do we need to sign a "labor contract"? This is essentially a smart contract. I am quite looking forward to how smart contracts in the Crypto field will be applied to digital world Agents, distributing economic benefits through a good measurement and pricing method after tasks are completed. This could be an opportunity for the combination of Agents and Crypto smart contracts.
06 What Will the Collaborative Relationship Between Humans and Agents Look Like?
Zhang Peng: Recently, in the direction of Coding Agents, two terms have been discussed quite a bit: "Human in the loop" and "Human on the loop." What are they exploring?
Zhong Kaiqi (Cage): "Human on the loop" refers to minimizing human decision-making in the loop, only participating at critical moments. It’s somewhat like Tesla's FSD, where the system warns humans to take over the throttle and brakes when it encounters a dangerous decision. In the virtual world, this usually refers to non-instantaneous, asynchronous human-machine collaboration. Humans can intervene in critical decisions that AI is uncertain about.
"Human in the loop," on the other hand, leans more towards AI occasionally "pinging" you to confirm something. For example, Minus AI has a virtual machine on its right side, where I can see in real-time what it is doing in the browser. This is like an open white box, allowing me to have a general idea of what the Agent intends to do.
These two concepts are not strictly black and white but rather exist on a spectrum. Currently, there is more "in the loop," as humans still need to approve many critical points. The reason is simple: software has not reached that stage yet, and when problems arise, someone must be responsible. The throttle and brakes cannot be eliminated.
It is foreseeable that in the future, for highly repetitive tasks, the final result will be that humans only look at summaries, and the level of automation will be very high. For some challenging problems, such as having AI analyze pathology reports, we can adjust the Agent's "false positive rate" to make it more likely to flag "issues," and then "on the loop," send these cases as emails to human doctors. In this way, although human doctors will have more cases to review, all cases judged as "negative" by the Agent can be smoothly approved. If only 20% of the pathology reports are genuinely challenging, then the workload of human doctors will have increased fivefold. Therefore, it is not necessary to be overly concerned about whether it is "in" or "on"; as long as we find a good combination point, we can achieve excellent human-machine collaboration.
Li Guangmi: The question that Peng Ge asked actually presents a huge opportunity regarding "new interactions" and "how humans and Agents can collaborate." This can be simply understood as online (synchronous) and offline (asynchronous). For example, when we have a live meeting, we must be online in real-time. However, if I, as a CEO, assign tasks to colleagues, the project advancement is asynchronous.
The greater significance here is that when Agents are widely implemented, how humans and Agents interact and how Agents interact with each other is worth exploring. Today, we still interact with AI through text, but in the future, there will be many ways to interact with Agents. Some may run automatically in the background, while others will require human oversight. Exploring new interactions is a significant opportunity.
07 When Will the "Killer Application" of Agents Arise Amidst Surplus Capabilities and Insufficient Demand?
Zhang Peng: Coding Agents are generally still working along the extension of IDEs. Will there be changes in the future? If everyone is crowded on this path, how can newcomers catch up with Cursor?
Zhong Kaiqi (Cage): IDEs are just an environment; replicating the value of an IDE itself is not very significant. However, creating Agents within an IDE or another good environment is valuable. I will consider whether its users are merely professional developers or if it can expand to include "citizen developers"—those white-collar workers with many automation needs.
What is currently lacking? It is not the supply capability, as products like Cursor have already amplified AI's coding supply capability by 10 times or even 100 times. Previously, if I wanted to create a product, I needed to outsource to an IT team, and the trial-and-error cost was very high. Now, theoretically, I just need to say a word and pay a $20 monthly fee to experiment.
What is currently lacking is demand. Everyone is trying to apply old demands to new technologies, which is somewhat like "looking for nails with a hammer." Most current demands are for creating landing pages or basic toy websites. In the future, we need to find a convergent product form. This is somewhat similar to when recommendation engines emerged; it was a great technology, and later a product form called "information flow" emerged, truly bringing recommendation engines to the masses. However, the AI Coding field has yet to find a killer product like "information flow."
Li Guangmi: I believe that Coding could potentially capture 90% of the value of the entire large model industry stage. How does this value grow? The first act today still serves 30 million programmers worldwide. For example, Photoshop serves around 20 to 30 million professional designers, which has a high barrier to entry. However, when tools like CapCut, Canva, and Meitu Xiuxiu emerged, possibly 500 million or more users could use these tools and create more popular content.
Code has an advantage; it is a platform for creative expression. Over 90% of tasks in society can be expressed through code, so it has the potential to become a creative platform. Previously, the barrier to application development was very high, and many long-tail demands were unmet. When the barrier is significantly lowered, these demands will be stimulated. What I look forward to is an "explosion of applications." The largest data generated by the mobile internet is content, and the largest content generated by this wave of AI may be new application software. This is akin to the difference between long video platforms like Youku and iQIYI and short video platforms like Douyin. You can think of large models as cameras, on top of which killer applications like Douyin and CapCut can be created. This may be the essence of "Vibe Coding," which is a new creative platform.
Zhang Peng: To enhance the output value of Agents, input also becomes very important. But in terms of products and technology, what methods can improve input quality to ensure better output?
Zhong Kaiqi (Cage): In terms of products, we cannot think that users not using the product well is the user's problem. The key term to focus on is "context." Can an Agent establish "context awareness"?
For example, if I am writing code in a large internet company, the Agent needs to not only look at my current code but also the entire company's relevant codebase, and even my conversations with product managers and colleagues on Feishu, as well as my previous coding and communication habits. Providing all this context to the Agent will make my input more efficient.
Therefore, for Agent developers, the most critical aspect is to create a robust memory mechanism and context connection capability, which is also a significant challenge for Agent infrastructure.
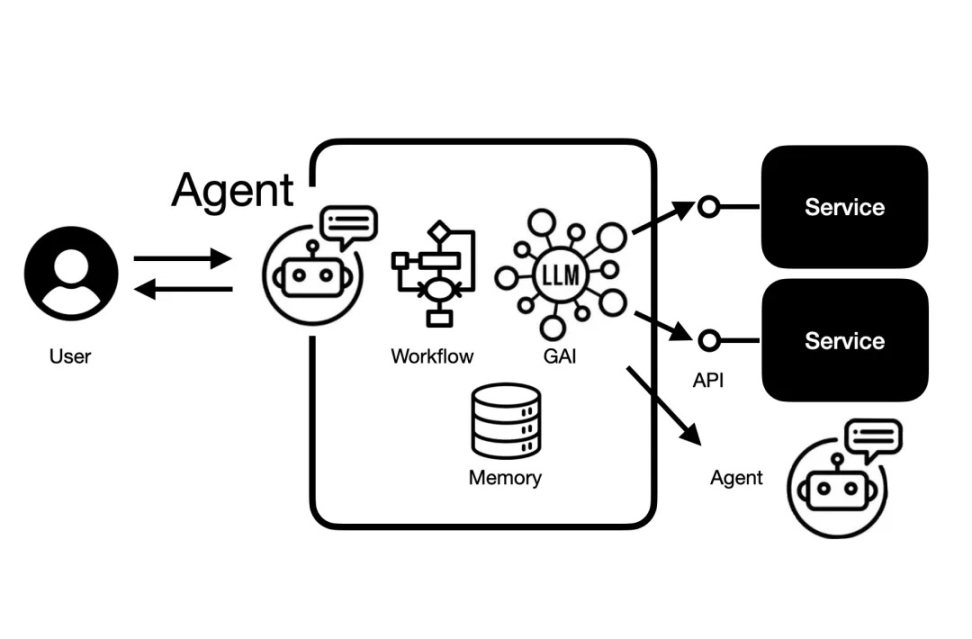
Challenges for Agents: Good memory mechanisms and context connections | Source: Retail Science
Additionally, for developers, it is important to effectively manage the cold start data for reinforcement learning and to define clear rewards. This reward implies how to break down a user's unclear needs when they express them. For instance, OpenAI's Deep Research provides four guiding questions when I ask something unclearly. In the process of interacting with it, I am also clarifying my own needs.
For today's users, the main focus should still be on how to express their needs clearly and how to validate those needs. While it is not necessary to achieve "start with the end in mind," there should be a general expectation of good and bad outcomes. When we write prompts, we should do so like writing code, with clear instructions and logic, which can help avoid a lot of ineffective outputs.
Li Guangmi: I would like to add two points. First, the importance of context. We often discuss internally that if context is well managed, there will be new opportunities at the level of Alipay or PayPal.
In the past, e-commerce focused on Gross Merchandise Volume (GMV), but in the future, it will focus on task completion rates. Task completion involves intelligence on one side and context on the other. For example, if I want to create a personal website, providing my Notion notes, WeChat data, and email data to AI will certainly enrich the content of my personal website.
Second, autonomous learning. After setting up the environment, it is crucial for the Agent to be able to iterate. If it cannot continuously learn and iterate, the result will be that it gets consumed by the model itself, as the model is a learning system. In the last wave of mobile internet, companies that did not engage in machine learning and recommendations did not grow significantly. If Agents cannot effectively manage end-to-end autonomous learning and iteration in this wave, I believe they will also struggle to succeed.
08 What Changes and Opportunities Exist Amidst the Competition Among Giants?
Zhang Peng: How can we determine whether the future capabilities of Agents will emerge as a super interface or be distributed discretely across various scenarios?
Zhong Kaiqi (Cage): I see a significant trend: first, it will definitely be multi-agent. Even for completing a task, in products like Cursor, the Agent responsible for code completion and the one for unit testing may be different, as they require different "personalities" and strengths.
Second, will there be changes in the entry points? I think entry points are a second-order question. The first thing that needs to happen is that everyone has many Agents and collaborates with them. These Agents will support a network, which I call a "Botnet." For example, in future shopping, more than 60% of fixed consumption may be completed by Agents on my behalf.
The same applies to productivity scenarios; in the future, daily meetings for programmers may be replaced by collaboration among Agents, which will push metrics anomalies and product development progress. Only when these occur will changes in entry points be possible. At that time, API calls will no longer primarily be made by humans but will be mutual calls between Agents.
Zhang Peng: What are the decision-making and action states of capable large companies like OpenAI, Anthropic, Google, and Microsoft regarding Agents?
Li Guangmi: A keyword that comes to mind is "differentiation." Last year, everyone was chasing GPT-4, but now there are more capabilities, and companies are starting to differentiate.
The first to differentiate was Anthropic. Because it came later than OpenAI and does not have as strong overall capabilities, it focused on Coding. I feel they have grasped the first major card leading towards AGI, which is the Coding Agent. They may believe that AGI can be achieved through Coding, bringing about instruction-following capabilities and Agent capabilities, creating a logically coherent closed loop.
However, OpenAI has more cards in hand. The first card is ChatGPT, which Sam Altman may want to turn into a product with 1 billion daily active users. The second card is its "o" series models (like GPT-4o), which have high expectations and can bring more generalization capabilities. The third card is multimodal; its multimodal reasoning capabilities have improved, which will also reflect in future generation tasks. Thus, Anthropic has grasped one major card, while OpenAI has grasped three.
Another major player is Google. I believe that by the end of this year, Google may catch up comprehensively. It has TPU, Google Cloud, top-tier Gemini models, as well as Android and Chrome. You cannot find another company globally that possesses all these elements and is almost entirely independent of external companies. Google's end-to-end capabilities are very strong; many people worry that its advertising business will be disrupted, but I feel it may find new product combinations, transforming from an information engine into a task engine.
Look at Apple; because it lacks its own AI capabilities, its iterations are very passive. Microsoft excels in developer tools, but Cursor and Claude have actually captured a lot of developer attention. Of course, Microsoft’s foundation is very stable, with GitHub and VS Code, but it must also possess very strong AGI and model capabilities. Therefore, you see it has announced that one of GitHub's preferred models has become Claude, and it is iterating its developer products. Microsoft must hold its ground in the developer space; otherwise, its foundation will be undermined.
So everyone is starting to differentiate. OpenAI may want to become the next Google, while Anthropic may want to become the next Windows (surviving on APIs).
Zhang Peng: What changes and opportunities exist in the infrastructure related to Agents?
Zhong Kaiqi (Cage): Agents have several key components. Besides models, the first is the environment. In the early stages of Agent development, 80% of the problems arose from the environment. For example, early AutoGPT either used Docker to start, which was very slow, or was deployed directly on local computers, which was very insecure. If an Agent is to "work" with me, I need to provide it with a "computer," hence the opportunity for environments arises.
Providing a "computer" has two major needs:
Virtual machines/sandboxes: Providing a secure execution environment. If a task goes wrong, it can roll back, the execution process cannot harm the actual environment, and it must be able to start quickly and run stably. Companies like E2B and Modal Labs are providing such products.
Browsers: Information retrieval is the biggest demand; Agents need to crawl information from various websites. Traditional crawlers are easily blocked, so a dedicated browser that can understand information is needed for Agents. This has led to the emergence of companies like Browserbase and Browser Use.
The second component is context. This includes:
Information retrieval: Traditional RAG companies still exist, but there are also new companies, such as MemGPT, which develops lightweight memory and context management tools for AI Agents.
Tool discovery: In the future, there will be many tools, requiring a platform similar to "Dazhong Dianping" to help Agents discover and select useful tools.
Memory: Agents need an infrastructure that can simulate the complex combination of human long-term and short-term memory capabilities.
The third component is tools. This includes simple searches as well as complex payments, automated backend development, etc.
Finally, as Agent capabilities strengthen, an important opportunity will be Agent security.
Li Guangmi: Agent infrastructure is very important. We can think "start with the end in mind"; three years from now, when trillions of Agents are executing tasks in the digital world, the demand for infrastructure will be immense, which will reconstruct the entire cloud computing and digital world.
However, today we still do not know what kind of Agents can scale, and what kind of infrastructure they will need. Therefore, this is a very good window period for entrepreneurs to co-design and co-create infrastructure tools with successful Agent companies.
I believe the most important aspects today are, first, virtual machines, and second, tools. For example, future Agent searches will definitely differ from human searches, leading to an enormous demand for machine searches. Currently, human searches across the internet may total 20 billion times a day; in the future, machine searches could reach hundreds of billions or even trillions of times. This type of search does not require sorting optimization for humans; a large database may suffice, presenting significant cost optimization and entrepreneurial opportunities.
09 When AI Is No Longer Just a Large Model, What Direction Will It Evolve Towards?
Zhang Peng: Agents are always intertwined with models. From today's perspective, what key milestones do you think model technology has achieved in the past two years?
Li Guangmi: I believe there are two key milestones. One is the paradigm of scaling laws represented by GPT-4, which indicates that expanding scale during the pre-training phase is still effective and can bring about generalization capabilities.
The second major milestone is the paradigm represented by the "o" series models, which signifies that "models can think." It significantly enhances reasoning capabilities through longer thinking times (chains of thought).
I feel that these two paradigms are the left and right arms of AGI today. On this basis, scaling laws have not stopped, and thinking patterns will continue to evolve. For example, scaling can continue in multimodal contexts, and the thinking capabilities of the "o" series can be integrated into multimodal systems, allowing for longer reasoning capabilities, which will greatly enhance the controllability and consistency of generated outputs.
I personally feel that the next two years may see faster progress than the past two years. We are currently in a state where thousands of top AI scientists worldwide are collectively driving a technological renaissance for humanity, with abundant resources and established platforms, leading to potential breakthroughs in many areas.
Zhang Peng: What technological milestones and leaps do you look forward to seeing in the AI field in the next year or two?
Zhong Kaiqi (Cage): The first is multimodal. Currently, the understanding and generation of multimodal content are still quite fragmented, but in the future, it will definitely move towards "unification," meaning the integration of understanding and generation. This will greatly expand the imagination of products.
The second is autonomous learning. I really like the concept of "the era of experience" proposed by Richard Sutton (the father of reinforcement learning), which means that AI enhances its capabilities through the experience of executing tasks online. This was previously unseen because there was no foundational world knowledge. However, starting from this year, this will be a continuous occurrence.

2024 Turing Award winner Richard Sutton | Source: Amii
The third is memory. If models can truly implement memory for Agents at the product and technical levels, the breakthroughs will be significant. Product stickiness will genuinely emerge. I feel that the moment GPT-4o started to have memory, I truly developed a connection to the ChatGPT application.
Finally, there is new interaction. Will there be new forms of interaction that are no longer just text input boxes? Because typing is actually quite a high barrier. In the future, will there be interaction methods that are more aligned with human intuition and instinct? For example, I have an "Always-on" AI product that continuously listens to me in the background, asynchronously thinks, and can capture key context at the moment my inspiration strikes. I think these are all things I look forward to.
Zhang Peng: Indeed, today we face both challenges and opportunities. On one hand, we cannot be overwhelmed by the speed of technological development; we must maintain continuous attention. On the other hand, today's AI products are transitioning from "tools" to "relationships." People do not form relationships with tools, but they will form relationships with an AI that has memory, understands them, and can resonate with them. This relationship is essentially about habits and inertia, which will also be an important barrier in the future.
Today's discussion has been very in-depth. Thank you, Guangmi and Kaiqi, for your wonderful sharing. Also, thank you to the audience in the live stream for your company. See you next time on "Tonight's Tech Talk."
Li Guangmi: Thank you.
Zhong Kaiqi (Cage): Thank you.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







