原文标题:《数据即资产:DataFi 正在开启新蓝海》
原文作者:anci_hu49074,Biteye 核心贡献者
「我们正处于全球竞相构建最佳基础模型的时代。计算能力和模型架构虽然重要,但真正的护城河是训练数据」
——Sandeep Chinchali,Story 首席 AI 官
从 Scale AI 谈起,聊聊 AI Data 赛道的潜力
要说本月 AI 圈最大的八卦,莫过于 Meta 展现钞能力,扎克伯格四处招募人才,组建了一支以华人科研人才为主的豪华 Meta AI 团队。领队正是年仅 28 岁、创建了 Scale AI 的 Alexander Wang。他一手创建了 Scale AI,目前估值 290 亿美金,服务对象既包括美国军方,也覆盖 OpenAI、Anthropic、Meta 等等的多家有竞争关系的 AI 巨头,都要依靠 Scale AI 提供的数据服务,而 Scale AI 的核心业务便是提供大量准确的标注数据(labeled data)。
为什么 Scale AI 可以从一众独角兽中脱颖而出?
原因就在于它早早发现了数据在 AI 产业中的重要性。
算力、模型、数据是 AI 模型的三大支柱。如果把大模型比成一个人的话,那么模型是身体、算力是食物,而数据,就是知识/信息。
在 LLM 拔地而起发展至今的岁月里,业界的发展重点也经历了从模型到算力的转移,如今大多数模型都已确立了 transformer 作为模型框架,偶尔创新 MoE 或 MoRe 等;各大巨头或者是自建 Super Clusters 完成算力长城,或者是和 AWS 等实力雄厚的云服务签订长期协议;搞定了算力的基础温饱,数据的重要性就逐渐凸显了。
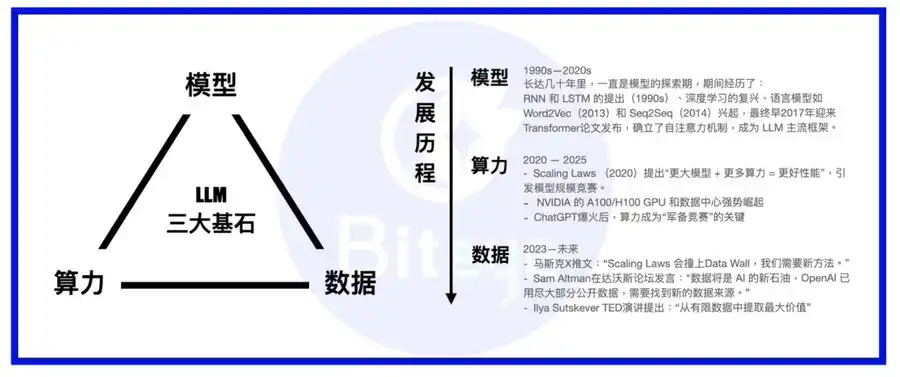
与 Palantir 等二级市场声名显赫的传统 To B 大数据公司不同,Scale AI 公司如其名,致力于为 AI 模型打造坚实的数据基础,其业务不止于对现有数据等挖掘,还将眼光投向更长远的数据生成业务,并试图通过不同领域的人工专家组成 AI trainer 团队,为 AI 模型的训练提供更加优质的训练数据。
如果你对这个业务不以为然,那么我们不妨先看看模型是如何训练的。
模型的训练分为两个部分——预训练和微调。
预训练的部分,有点像人类的婴儿逐渐学会说话的过程,我们通常需要的是喂给 AI 模型大量从网上爬虫获取的文本、代码等信息,模型通过自我学习这些内容,学会说人话(学术上叫做自然语言),具备基础的沟通能力。
微调的部分,就类似去学校读书,通常有明确的对错、答案和方向。学校会根据各自的定位,把学生们培养成不同的人才。而我们也会通过一些事先处理好的、有针对的数据集,把模型训练得具备我们期待的能力。

至此,聪明的你可能已经明了,我们需要的数据也分为两部分。
· 一部分数据不需要经过太多处理,足够多就好,通常来自例如 Reddit、Twitter、Github 等大型 UGC 平台的爬虫数据、公开文献数据库、企业私有数据库等。
· 另一部分,就像专业的课本,需要精细的设计和筛选,确保能够培养模型特定的优良品质,这就需要我们进行一些必要的数据清洗、筛选、打标签、人工反馈等工作。
这两部分数据集,就构成了 AI Data 赛道的主体。不要小看这些看似没什么科技含量的数据集,目前主流观点认为,随着 Scaling laws 中算力优势的逐渐失效,数据将成为不同大模型厂商保持竞争优势的最重要支柱。
随着模型能力的进一步提升,各种更加精细、专业的训练数据将成为模型能力的关键影响变量。如果我们更进一步把模型的训练比作武林高手的养成,那么优质的数据集,就是最上乘的武功秘籍(要想把这个比喻补充完整,也可以说算力是灵丹妙药、模型是本身资质)。
纵向来看,AI Data 也是一个具备滚雪球能力的长期主义赛道,随着前期工作的积累,数据资产也将具备复利能力,越老越吃香。
Web3 DataFi:天选 AI Data 沃土
相比 Scale AI 在菲律宾、委内瑞拉等地组建的几十万人的远程人工标记团队,Web3 在进行 AI 数据领域上有天然的优势,DataFi 的新名词也随之诞生。
在理想情况下,Web3 DataFi 的优势如下:
1. 智能合约保障的数据主权、安全和隐私
在现存公开数据即将被开发用尽的阶段,如何进一步挖掘未公开数据、甚至是隐私数据,是获取拓展数据源的一个重要方向。这就面临一个重要的信任选择的问题——你是选择中心化大公司的一纸合同买断制,出卖自己手上的数据;还是选择区块链上的方式,继续把数据 IP 握在手中的同时,还能够通过智能合约清晰明了的明白:自己的数据被何人何时何事使用。
同时,对于敏感信息,还有可以通 zk、TEE 等方式,保证你的隐私数据只有守口如瓶的机器经手,而不会被泄露。
2. 天然的地理套利优势:自由的分布式架构,吸引最适合的劳动力
或许是时候挑战一下传统的劳动生产关系了。与其像 Scale AI 这样全世界寻找低价劳动力,不如发挥区块链的分布式特点,并通过由智能合约保障的公开、透明的激励措施,让分散在全世界的劳动力都能够参与到数据贡献中去。
对于数据打标、模型评估等人力密集工作,相比于中心化的建立数据工厂的方式,使用 Web3 DataFi 的方式还有利于参与者的多样性,这对避免数据的偏见也有长远意义。
3. 区块链明确的激励和结算优势
如何避免「江南皮革厂」式的悲剧?自然是用智能合约明码标价的激励制度,取代人性的阴暗。
在不可避免的去全球化背景下,如何继续实现低成本的地理套利?满世界开公司显然已经更难了,那不如绕过旧世界的藩篱,拥抱链上结算的方式吧。
4. 有利于构建更加高效、开放的「一条龙」数据市场
「中间商赚差价」是供需双方永远的痛,与其让一个中心化的数据公司充当中间商,不如在链上创建平台,通过像淘宝一样公开的市场,让数据的供求双方能够更加透明、高效的对接。
随着链上 AI 生态的发展,链上的数据需求将更加旺盛、细分和多样,只有去中心化的市场能够高效的消化这种需求,并转化成生态的繁荣。
对于散户而言,DataFi 也是最有利于普通散户参与的去中心化 AI 项目。
虽然 AI 工具的出现一定程度降低了学习门槛,去中心化 AI 的初衷也是打破当下巨头垄断 AI 生意的格局;但不得不承认,当前的许多项目对于毫无技术背景的散户而言,可参与性并不强——参与去中心化算力网络挖矿往往伴随着昂贵的前期硬件投入,模型市场的技术门槛又总能轻易让普通参与者望而却步。
相比之下,是普通用户可以在 AI 革命中抓住的为数不多的机会——Web3 让你不需要签下一份数据血工厂的合同,只需要鼠标一点登录下钱包,就可以通过完成各种简单的任务参与其中,包括:提供数据、根据人脑的直觉和本能对模型进行打标、评估等简单工作、或者进一步利用 AI 工具进行一些简单的创作、参与数据交易等。对于撸毛党老司机们,难度值基本为零。
Web3 DataFi 的潜力项目
钱流向了哪里,方向就在哪里。除了 Web2 世界中 Scale AI 获 Meta 投资 143 亿美金、Palantir 一年内股票狂飙 5 倍+以外,Web3 融资中,DataFi 赛道的表现也十分优秀。这里我们对这些项目做一个简单的介绍。
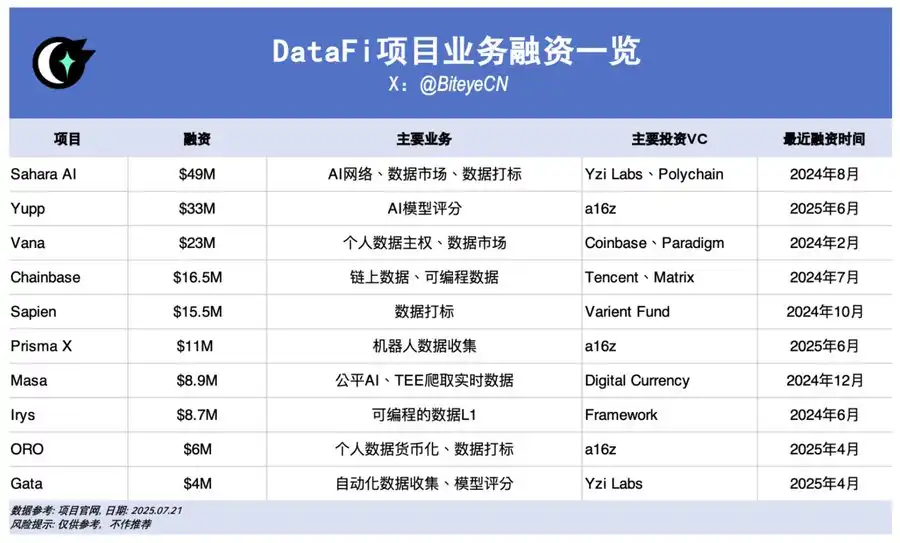
Sahara AI,@SaharaLabsAI,融资 4900 万美金
Sahara AI 的最终目标是打造一个去中心化 AI 的超级基础设施和交易市场,试水的第一个板块就是 AI Data,其 DSP(Data Services Platform,数据服务平台)公测版将于 7 月 22 日上线,用户可以通过贡献数据、参与数据打标等任务获得代币奖励。
链接:app.saharaai.com
Yupp,@yupp_ai,融资 3300 万美金
Yupp 是一个 AI 模型的反馈平台,主要收集用户对模型输出内容的反馈。当前的主要任务是用户可以对比不同模型对同一个 prompt 的输出,然后评选出个人认为更好的那一个。完成任务可以获取 Yupp 积分,Yupp 积分可以进一步兑换成 USDC 等法币稳定币。
链接:https://yupp.ai/
Vana,@vana,融资 2300 万美金
Vana 的重点在于将用户的个人数据(如社交媒体活动、浏览记录等)转化为可货币化的数字资产。用户可以授权将个人数据上传到 DataDAOs 中相应的数据流动性池(DLP)中,这些数据将会被汇集起来,用于参与 AI 模型训练等任务,用户也将获得相应的代币奖励。
链接:https://www.vana.org/collectives
Chainbase,@ChainbaseHQ,融资 1650 万美金
Chainbase 的业务聚焦在链上数据,目前已覆盖 200 多条区块链,将链上活动化为结构化、可验证且可货币化的数据资产,供 dApp 开发使用。Chainbase 的业务主要通过多链索引等方式获得,并通过其 Manuscript 系统和 Theia AI 模型对数据加工,普通用户目前可参与度不高。
Sapien,@JoinSapien,融资 1550 万美金
Sapien 的目标是将人类知识大规模转化为高质量的 AI 训练数据,任何人都可以在平台上进行数据标注工作,并通过同伴验证的方式,保证数据的质量。同时鼓励用户建立长期信誉、或通过质押的方式做出承诺,赚取更多奖励。
链接:https://earn.sapien.io/#hiw
Prisma X,@PrismaXai,融资 1100 万美金
Prisma X 想做机器人的开放协调层,其中物理数据收集是关键。这个项目目前处于早期阶段,根据近期刚发布的白皮书推测,参与方式可能有投资机器人收集数据、远程操作机器人数据等方式。目前开放基于白皮书的 quiz 活动,可以参与赚积分。
链接:https://app.prismax.ai/whitepaper
Masa,@getmasafi,融资 890 万美金
Masa 是 Bittensor 生态的头部子网项目之一,目前运营有 42 号数据子网和 59 号 Agent 子网。数据子网致力于提供实时访问数据,目前主要是矿工通过 TEE 硬件爬取 X/Twitter 上的实时数据,对于普通用户来说,参与难度和成本都比较大。
Irys,@irys_xyz,融资 870 万美金
Irys 专注于可编程数据存储和计算,旨在为 AI、去中心化应用(dApps)和其他数据密集型应用提供高效、低成本的解决方案。数据贡献方面目前看普通用户可以参与的不多,但当前测试网阶段有多重活动可以参与。
链接:https://bitomokx.irys.xyz/
ORO,@getoro_xyz,融资 600 万美金
ORO 想做的是赋能普通人参与 AI 贡献。支持的方式有:1. 链接自己的个人账号贡献个人数据,包括社交账号、健康数据、电商金融等账号;2. 完成数据任务。目前测试网已上线,可以参与。
链接:app.getoro.xyz
Gata,@Gata_xyz,融资 400 万美金
定位为去中心化数据层,Gata 目前推出了三个产品 key 参与:1. Data Agent:一系列只要用户打开网页就可以自动运行处理数据的 AI Agent;2. AII-in-one Chat:类似与 Yupp 的模型评估赚取奖励的机制;3. GPT-to-Earn:浏览器插件,收集用户在 ChatGPT 上的对话数据。
链接:https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
怎样看当下的这些项目?
目前看这些项目壁垒普遍不高,但要承认的是,一旦积累了用户和生态粘性,平台优势会迅速累积,因此早期的应在激励措施、用户体验上着重发力,只有吸引到足够的用户才能做成数据这单大生意。
不过,作为人力密集型的项目,这些数据平台在吸引人工的同时,也要考虑如何管理人工、保障数据产出的质量。毕竟 Web3 许多项目的通病——平台上大部分用户都只是无情的撸毛党——他们为了获得短期的利益往往牺牲质量,如果放任他们成为平台主力用户,势必会劣币驱逐良币,最终使数据质量得不到保障,也无法吸引来买家。目前我们看到 Sahara、 Sapien 等项目都已在数据质量上有所强调,努力与平台上的人工建立长期健康的合作关系。
另外,透明度不够,是当下链上项目的又一问题所在。诚然,区块链的不可能三角,让许多项目在启动阶段都只能走一条「中心化带动去中心化」的道路。但如今越来越多的链上项目给人的感观,更像「披着 Web3 皮的 Web2 旧项目」——公开的可链上追踪的数据寥寥无几,甚至路线图上也很难看出公开、透明的长期决心。这对于 Web3 DataFi 的长期健康发展无疑是有毒的,我们也期待更多项目常怀初心,加快开放、透明的步伐。
最后,DataFi 的 mass adoption 路径也要分为两个部分看:一部分是吸引到足够多 toC 参与者加入到这个网络,形成数据采集/生成工程的生力军、AI 经济的消费者,组成生态闭环;另一部分则是得到目前主流 to B 大公司的认可,毕竟短期看财大气粗的他们才是数据大单的主要来源。这方面我们也看到 Sahara AI、Vana 等都取得了不错的进展。
结尾
宿命论一点说,DataFi 是用人类智能长期哺育机器智能,同时以智能合约为契约,保障人类智能的劳动有所收益,并最终享受机器智能的反哺。
如果你在为 AI 时代的不确定性焦虑,如果你在币圈的沉浮中依然怀有区块链理想,那么跟随一众资本大佬的脚步,加入 DataFi 不失为一个顺势而为的好选择。
本文来自投稿,不代表 BlockBeats 观点。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







