After three years, I can no longer do industry research without AI assistance. To achieve this, I have built a series of skills and auxiliary systems to solve information screening, summarization, connection, verification, and sedimentation.
It wasn't until this week, after deeply experiencing Claude Code's Dynamic Workflows, that I realized the true meaning of the phrase "one should not fight against the great era."
Once again, I pondered: what type of deep research should be done by humans in the AI era, and how can I build a collaborative and complementary relationship with AI?
1. Starting from the pitfalls of research
Conducting technical research is actually filled with traps (for both humans and AI), as a large amount of information is received right from the start, with viewpoints increasing and conclusions becoming increasingly vague. Therefore, it's essential to always return to the original goal.
This has always been the reason why AI is not excellent enough, because from the perspective of attention and association, it is more constrained by the current amount of information than humans and is weak in truly valuable cross-disciplinary associations.
Of course, where AI excels is its execution capability, which, as an agent, can layer by layer search, summarize, and conclude, completely avoiding the loss of details.
Although I haven't published much on public accounts in the past six months, I have been comprehensively paying attention to and researching almost all mainstream battlefields in the industry, supported by my own deep-research system.
Faced with the launch of the Dynamic Workflows feature on Claude Code last week, I wanted to see whether its default capabilities could completely surpass my own.
2. What is Dynamic Workflows?
Dynamic Workflows have a core idea: before executing a task, AI automatically designs what workflow should be used to complete this task, and then starts execution.
This differs fundamentally from the "planning mode" and "skills" we used before. Planning mode breaks tasks down into finer parts but does not necessarily adhere to any reasonable workflow; only with the arrangement of your prompts can it possibly add acceptance criteria (which is crucial for research). Similarly, it can only better preset some harness rules if prompted.
However, dynamic workflows automatically incorporate acceptance logic, result convergence, and adversarial verification.
The activation method is very simple: just use /deep-research in cc and provide some research templates and entry materials. If you want to use the dynamic workflow capability alone, you can use a prompt or simply say ultracode. Note that the token consumption before use is about dozens of times the usual.
3. Six built-in workflow modes
The underlying structure of dynamic workflows is summarized by the official six core scheduling modes, which is why it is stronger than ordinary dialogue/agent/skill.
In fact, behind these six modes, there are only two core questions: how to break down the task? How to merge the results? Dividing into six types is essentially a permutation and combination of these two.
3.1 Routing mode (Classify-And-Act)
First, an agent identifies the task type, and then dispatches the task to the most suitable specialized agent to perform it. The core logic is the logic of routing selection, rather than parallelization or iteration. A task only follows one path, and other paths do not execute at all.
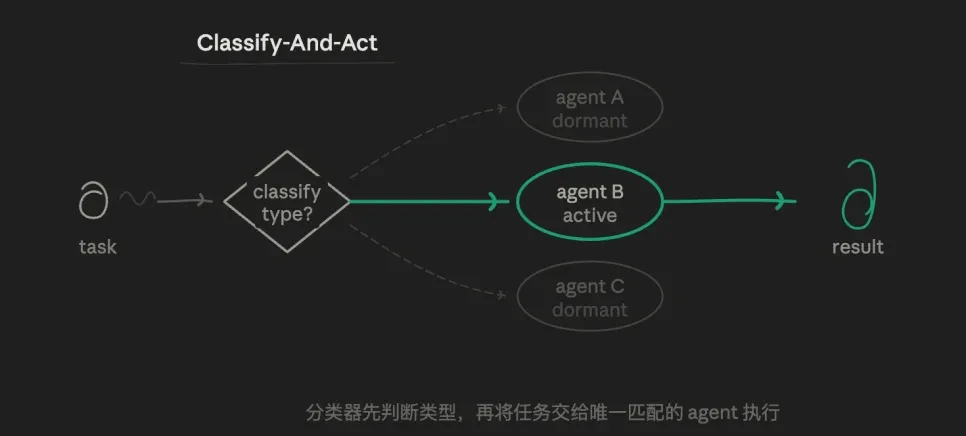
For example, I can set up three preset sub-agent roles: one strict data verification analysis agent, one writing output agent, and one challenge agent specialized in finding loopholes. The routing layer will determine who is suitable for the current sub-task, rather than letting one agent handle everything.
The value of this model lies in its precision and thrift; each agent's prompts can be highly independent, undisturbed by other objectives, forming an exploration with vertical depth. Token consumption is at its lowest, and response speed is the fastest. The boundaries of responsibilities are very clear.
However, the drawbacks are also significant: it has weak handling capabilities for tasks with ambiguous boundaries (such as "both a technical issue and an account issue").
3.2 Splitting and Merging (Fan-out & Merge)
This is also my most commonly used mode. The core logic is parallelism + merging. The task is divided into N independent sub-tasks running simultaneously, and when all are completed, they are merged.
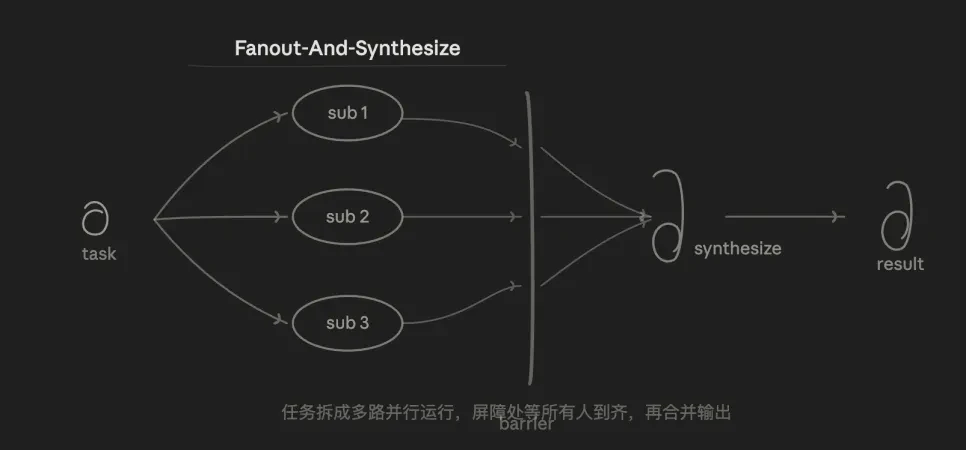
The advantage lies in speed and isolation. Total time is roughly equal to the slowest sub-task, rather than the sum of all sub-tasks. Each sub-task has an independent context that does not interfere with others, and noise from one sub-task does not pollute others.
The weakness is that the token cost is serially N times, and merging layer (Synthesize) also poses difficulty—how to merge outputs with inconsistent N-route structures is a design challenge. Poorly defined sub-tasks can lead to omissions or redundant overlaps.
3.3 Adversarial Verification
The core logic is verification. For the same conclusion, multiple agents are tasked to challenge from a "refutation" perspective; over half of the votes count as a pass.
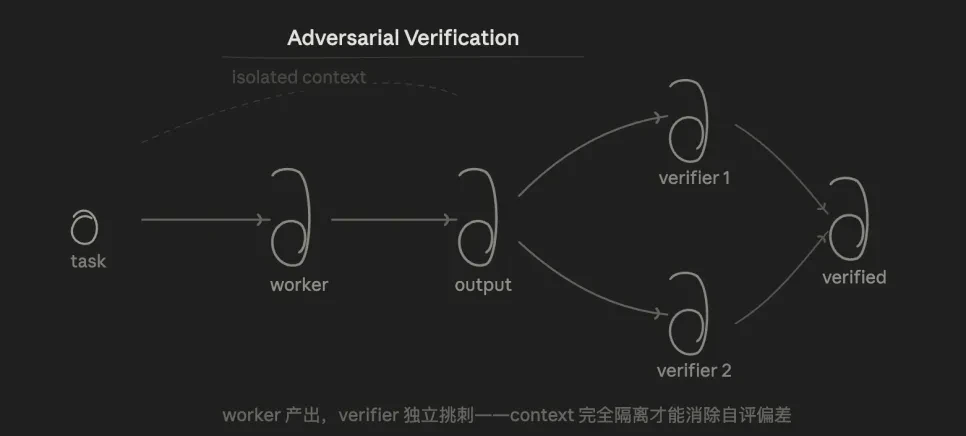
The advantage is that, since the Verifier does not know the Worker’s thought process and only looks at the results, it structurally eliminates self-assessment bias that occurs when the model checks the code it has written.
This mode solves a long-standing issue that has troubled me: we often converse with AI in casual language, but AI tends to respond according to your expectations, easily leading to "confirmation bias." Adversarial verification forces AI to look for counterexamples and verify based on data and experiments, rather than conforming to your ideas.
However, if it provides incorrect judgments during verification, it may lead the Worker astray to cater to the Verifier. Therefore, verification should ideally be based on reproducible facts rather than viewpoints.
As a joke, if you let AI find problems, it can endlessly find issues, so you need to constrain the boundaries of what it looks for.
3.4 Generation and Filtering (Generate & Filter)
The core logic is divergence followed by convergence. First, a surplus of candidates is deliberately generated, and then a rubric is used to eliminate the lesser options, retaining only the high-confidence results for output.
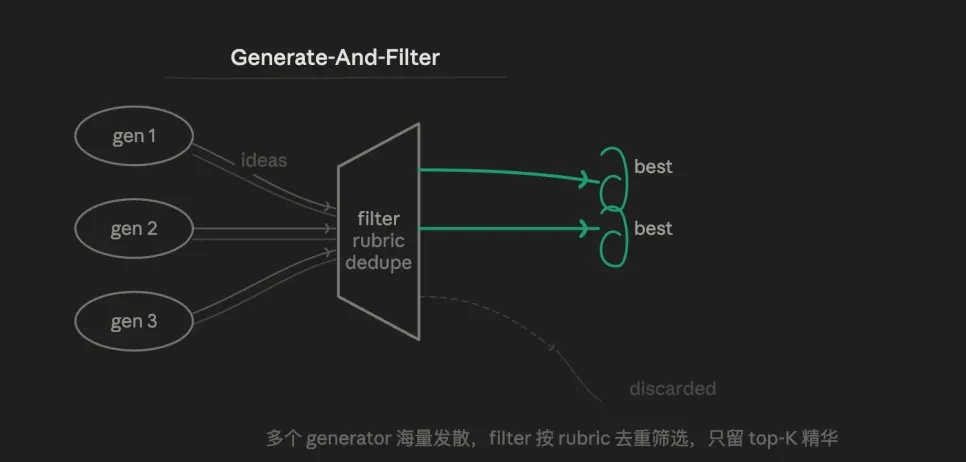
Instead of having one agent output a "decent" answer, it is better to have it generate ten, and then use the verification layer to filter. Therefore, the strength lies in diversity. Multiple Generators can employ different strategies and prompts to produce solutions that humans might not foresee, and the filtering step concentrates the quality of the final output.
The weakness is that the quality of the Filter's rubric directly determines the final effect; an error in rubric design nullifies the process.
It is suitable for scenarios where the correct answer is unknown in advance, needs to choose the best among multiple possibilities, and has a clear demand for diversity.
It only superficially resembles Fanout-And-Synthesize: both are "multi-path parallel → single output," making it easy to confuse.
The key difference lies in intent: Fanout works on different parts of the task, resulting in complementary outcomes, with all paths contributing when merged; Generate-And-Filter deals with the same task, resulting in competitive outcomes, with most being discarded upon merging. The former is like a "puzzle," the latter is like a "beauty pageant."
3.5 Tournament mode
The core logic is competitive elimination. N agents independently work on the same task, eliminating pairwise in rounds to ultimately select the best solution.
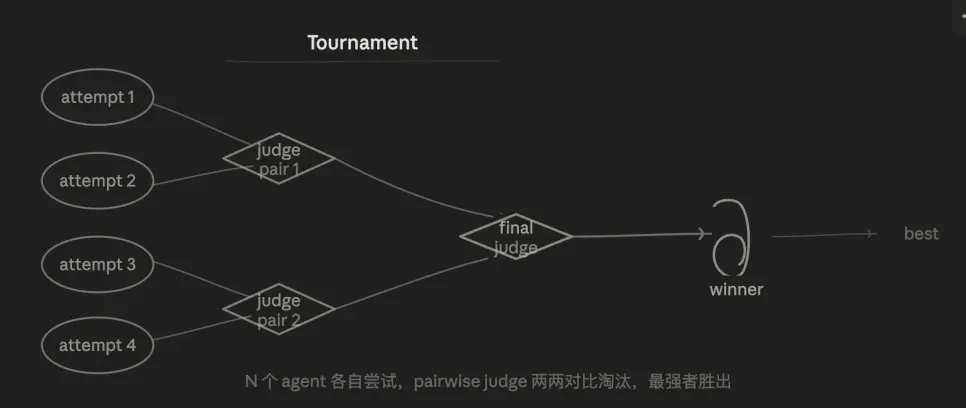
I have done this manually before—running two or three versions of the same code change and then having AI compare which is better. Now it can be directly integrated into the workflow.
The advantage is the stability of assessment. Pairwise comparisons ("Which is better, A or B?") are much more stable than absolute ratings ("Rate A"), as it eliminates the issue of rating standard drift. Results go through multiple rounds of competition, ensuring the credibility of the final winner.
It also superficially resembles Generate-And-Filter: both select the best among multiple candidates. The key difference lies in the selection mechanism: Tournament uses pairwise judging, allowing candidates to compete against each other. When the rubric is hard to quantify and judgment is essentially relative, it becomes more reliable.
3.6 Loop mode
The core logic is adaptive iteration, continuously trying, collecting error information upon resistance, supplementing context, and retrying until it meets acceptance criteria.
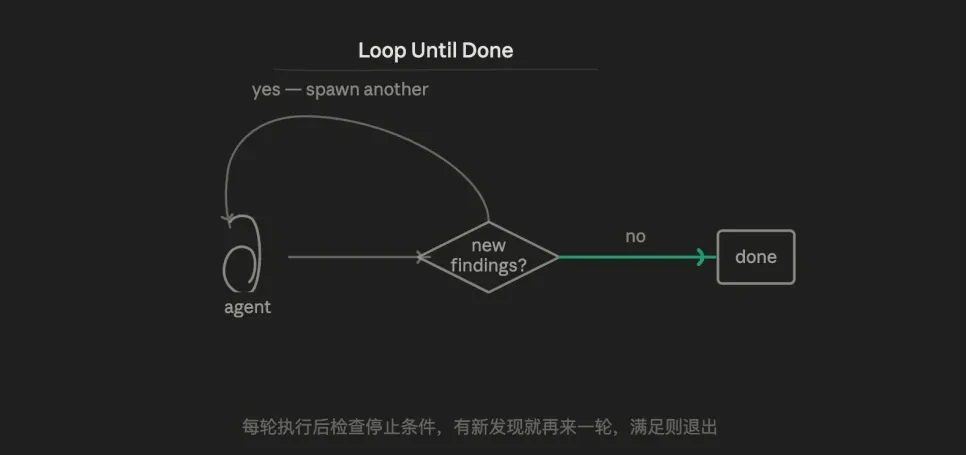
Essentially, it counteracts AI's randomness: by trying multiple times, it will eventually hit upon better results. But a more mature approach would be to combine adversarial verification, allowing each iteration to be executed with more information, rather than relying purely on randomness.
The advantage lies in handling tasks with unknown workloads. The other five modes assume task boundaries are well-defined; Loop Until Done is the only mode that can handle "not knowing how many rounds to do."
The weakness is the potential risk of losing control—if the stopping condition is poorly designed, it can lead to infinite loops. Each round's agent operates in a new context, unable to accumulate cross-round status (unless explicitly written to a file).
4. My own skill and the Battle with official workflows
Before Dynamic Workflows came out, I had specifically designed my own deep-research system. The logic of my skill is roughly as follows:
- Provide only a simple piece of information (e.g., a project has launched a new feature).
- Let AI search all relevant materials: official documents, source code, market sentiment.
- Compress the information into meaningful summaries.
- Multiple agent roles perform adversarial analysis and generate reports.
- Automatically deduplicate, as multiple agents tend to produce high content overlap.
I found it quite useful after using it for a while. However, it has a fundamental flaw: a lack of goal-oriented convergence.
Moreover, even with step five's deduplication, it often removes valuable information; if deduplication is not performed, the skill can easily provide a lengthy article, containing comprehensive information, but without directly telling you "what this means for you, and what you should do."
Research is meant to serve “decision-making,” which is why many skills can only stop at the research itself, achieving 80 points, but lacking the crucial remaining 20 points.
This leads to the situation where AI, after completing preliminary research, requires another ten rounds of thinking and conversation to arrive at a satisfactory and comprehensive conclusion.
What has the official dynamic workflow added?
Through several complex research task experiments this week, I discovered that the built-in deep research workflow in Claude Code (note that it is not just a skill, but a module compiled into cc) has added several key links compared to my own skill:
- Problem decomposition layer: it doesn't start searching directly but first asks questions—breaking my question into several sub-questions: what do you really want to clarify? What does this matter to you? What dimensions are worth deepening? I used to skip this step.
- Credibility assessment: assesses the falsifiability of each piece of information, similar to the authority scoring in traditional SEO—are the sources credible? How many citations are there? This is a step I hadn’t thought to add before.
- Cross-deletion rather than average merging: my previous method was to select all conclusions equally, leading to large documents. Dynamic workflows take multiple-agent votes on each conclusion; those with insufficient votes are deleted, rather than simply merging.
- Goal-oriented output: the final report is not just an information pile but provides judgments and suggested plans centered around your original goals. The key to achieving this is its scheduling ability with multiple sub-agents; the reason my skill often lacked final goal orientation was that after vast amounts of information, the weight of instructions diminished.
What problems do these mechanisms solve?
They address several typical issues when AI performs long tasks:
Goal drift: the task starts in a good state, but midway it loses focus. By the end, it struggles to regain rhythm—similar to human attention drifting during a lecture. The longer the task, the more pronounced it becomes.
Premature stopping: AI might think it has "completed" upon encountering challenges and stop when the acceptance criteria haven't been met.
Context pollution: when a single agent performs a complex task, a large amount of preceding prompts compresses subsequent execution space. A better method is to keep the preceding prompts within a few kilobytes and distribute the context across multiple agents.
Output bias: AI tends to answer in line with your expectations, and casual questioning more easily triggers this issue.
Dynamic Workflows address these four issues in a structured way: automatically adding acceptance criteria to prevent premature stopping; isolating contexts in parallel; adversarial verification offsetting output bias; and decomposing questions to constrain AI to understand goals before acting.
5. Conclusion
Finally, as a long-time researcher, I am amazed by this new mechanism in CC. Its six built-in modes—routing selection, splitting and merging, adversarial verification, generation and filtering, tournament, and loop—cover most scheduling needs for complex research tasks.
It eliminates the need for me to manually design agent scheduling, and I no longer need to handle deduplication and cross-verification, as these are built into the workflow itself.
It is especially suitable for exploring questions where information is scarce or developmental in nature, as the innate multi-agent scheduling combined with the task’s goal decomposition further enhances its versatility. In fact, three years ago, AI effectively handled solving extremely clear small problems with multiple constraints, but the true qualitative change in AI lies in its versatility, which sets it apart from competitors—transforming from simple coding into a true agent, adapting to any problem.
Thus, Dynamic Workflows are not "smarter single-instance dialogues," but rather structured the research process itself.
What used to require initiating over a dozen independent dialogues for research can now be compressed to 3-4 times. Although the corresponding token consumption has grown by several dozen times.
So why still 3-4 times? I believe the root cause lies in the differences in these requirements.
The first is the stringency of the verification mechanism. I mainly conduct research on new technologies in blockchain, where many matters are lagged in official documentation, with more reliable references in open-source code, on-chain transactions, and other data. Currently, AI still defaults to official documents rather than factual verification.
The second is fully cross-disciplinary deep thinking. This can be addressed to some extent through the workflow presets (pre-defining various dimensions of sub-agents) to think about the same problem. However, AI still excels more in mainstream thinking models and tends to fall short in addressing very new, profound issues that lack data basis.
The third is solution design and verification. The significance of a solution lies not in proposing it but in verifying and supporting it, relying on the assessment of existing mechanisms, inputs, and costs. While AI can certainly perform better with good training, this could contradict versatility.
Finally, the extreme condensation of information requires understanding the audience's level of familiarity with the information, as some people need anthropomorphized expressions due to a lack of background, while others need compelling one-liners to move them.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。




